こんにちは。カスタマーリライアビリティエンジニアの峯 (ニックネーム: mike) です。
私は趣味でアクアリウムをやっています。
アクアリウムで重要なのは水温や湿度の維持です。高すぎても低すぎてもいけません。そこでヒーターを使い調節するわけですが、故障や設定ミスの可能性があります。また、外気温の影響を受けて設定とは異なる水温や湿度になる場合もあります。
一方でアクアリウム用品には温湿度を監視したり、遠隔からヒーターを制御できるような製品はほとんどなく、異常にすぐに気づけません。そのため私はアクアリウムの IoT 化を目論んでおり、SORACOM を利用してAWSに水槽のデータを収集・監視できないかと考えています。
今回は、IoTのデータ活用の中でも「異常検知」に注目して、アクアリウムの水温の異常をリアルタイムで知るアーキテクチャーを紹介します。

構成
今回検証した構成は以下です。 Amazon Kinesis Data Analyticsを利用して異常検知をしています。構成は4つのセクションに分かれています。それぞれ解説します。
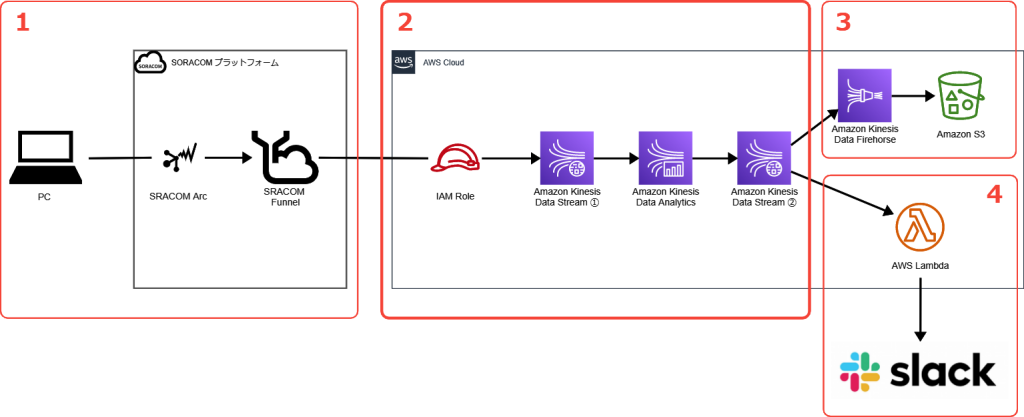
セクション1: 温度データの送信
このセクションでは、温度データのセンシングと送信を行います。
今回はパソコンを「疑似的な温度センサー」として利用しました。実際の温度センサーを利用するよりも、正常時・異常値を作りやすくするためです。
通信部分には「SORACOM Arc」を使っています。この通信サービスを使うとWireGuardというVPNを通じて、後述するSORACOM FunnelといったSORACOM プラットフォーム上の各種IoT向けサービスが利用可能となります。
Wi-Fi上でも使えるため、今回のようにパソコンを疑似的にIoTデバイスのように使うことも可能です。
Amazon Kinesis Data Analytics へのデータ送信には、クラウドアダプタサービス「SORACOM Funnel」を利用しています。ソフトウェア開発をすることなく、IoTデバイスからのデータをSORACOM Funnel が対応しているクラウドサービスへデータ転送ができます。
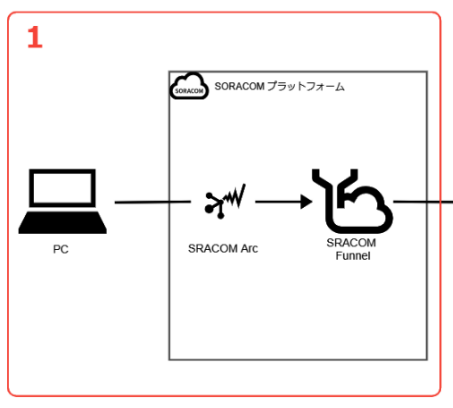
セクション2: Amazon Kinesis Data Analyticsで異常検知
このセクションでは、Amazon Kinesis Data Analytics(以下、Analytics)による異常検知を行います。
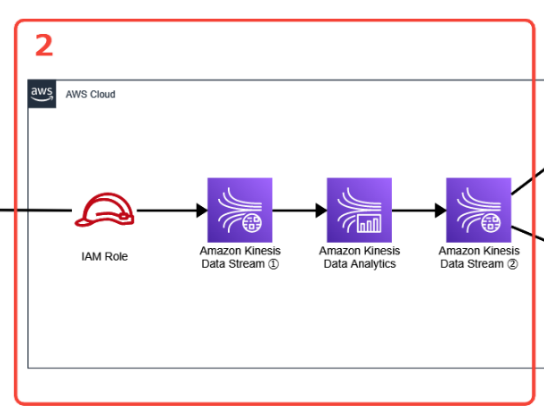
SORACOM Funnelからは一旦 Amazon Kinesis Data Streams(以下、Streams)を通すようにしています。一見面倒に見えますが、これはそれぞれ役割分担があるためです。データの受け付けや変換・流量制御といった処理をStreamsが行い、流れてきたデータ解析自体はAnalyticsがするといった形です。そうすることで、それぞれの機能が汎用的になるため、他のサービスとの組み合わせ(パイプライン構築)がしやすくなるメリットがあります。
実際、Analyticsでの解析結果は再度Streamsに引き渡され、そこからAmazon Kinesis Data Firehose経由でAmazon S3に保存したり、AWS Lambda経由でのSlack連携に利用しています。
Analyticsでの解析に話を戻すと、温度データを受け取り、RANDOM CUT FORESTという「異常なデータポイントを検出する」アルゴリズムで異常の度合い(異常値スコア)を算出します。
異常の検出には「25℃以上だったら」といった固定的なルールでも実現できそうですが、例えば日中での緩やかな水温上昇による25℃と、ヒーター故障による急激な25℃では意味が異なるわけです。そこで、アルゴリズムの適用で正常と異常を見分けようとしています。
実際にはAnalyticsが算出した異常値スコア(Anomaly score)の高低によって、最終的に判断します。今回は何度かテストをしてみたところ、異常値スコアが1.5以上の場合は異常と判定できそうでした。この辺りは、皆さんも実際にテストデータと異常値スコアを見比べて判断していくことになると思います。
異常検知が可能な、その他のAWSサービス
機械学習プラットフォームのAmazon SageMaker や、ログ・モニタリングサービスのAmazon CloudWatchでも異常検知は可能です。今回は、IoTデータのパイプライン構築が手軽なAmazon Kinesis Data Analyticsを利用しました
セクション3: Amazon S3 へデータ蓄積
解析結果は、異常値スコアの状況に寄らず全てAmazon S3に保存するようにしました。
先の異常値スコアの見極めにも使えますし、また運用後でも時系列データとして利用可能になります。そのため、Amazon S3 に蓄積しておくと良いでしょう。
セクション4: 異常時はSlackへ通知
ここが本来の目的になります。すなわち、異常時はSlackへ通知する仕組みです。
今回は AWS Lambda を経由してSlackに通知しています。異常値スコアが一定以上(私の例では1.5)を越えた場合にAWS Lambdaを呼び出すようにしています。
この仕組みで即座に知ることができるようになりました。一方で少し動かしてみて、2つの改善が必要なこともわかりました。1つ目は異常判定毎に毎度通知されることと、2つ目は正常判定時の復旧報が無い事です。
これら2つは「状態管理」をすれば解決しそうな事もわかりました。具体的には、一度異常状態となったら、次以降の異常判定を受け取っても通知しないようにしたり、また、正常状態を受け取ったら通知するといった形です。実際に構築してみて気づいた点としては良かったと感じています。
実際の構築のポイント
Amazon Kinesis Data Analyticsで、実際に異常検知をするところをご紹介します。
Analytics には下記の2種類がありますが、今回はRANDOM_CUT_FOREST 関数が利用可能な Amazon Kinesis Data Analytics for SQL を利用します。
| Amazon Kinesis Data Analytics for Apache Flink and Studio | ストリームデータをリアルタイムでインタラクティブにクエリできる開発環境で、 Apache Flink に基づいた処理や分析を作成できるサービス。 |
| Amazon Kinesis Data Analytics for SQL | SQLを使用して処理や分析を作成できるサービス。 |
Analytics の最初のステップでは、処理の対象となるソース(入力)と、処理後のデータの送信先(出力)を指定します。下記のようにそれぞれ アプリケーション内での名前を設定し、SQL文を記載します。送信先は今回は 1 つの Amazon Kinesis Data Streams ですが複数設定することも可能です。


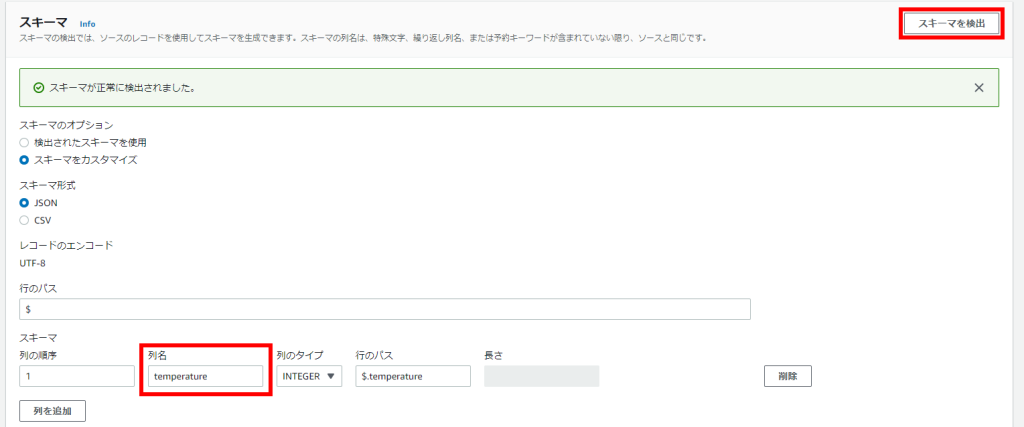
ちなみにソースの Amazon Kinesis Data Stream にデータを流せばソースのスキーマを自動検出できます。今回は後ほど流すサンプルデータの `temperature` スキーマのみです。
今回は RANDOM_CUT_FOREST 関数を利用します。ランダムカットフォレストはよく知られた機械学習のアルゴリズムです。この関数の利用時には、学習に必要なハイパーパラメータも指定します。デフォルト値もありますが、用途に併せて設定するのが望ましいです。今回は検証ですばやく結果が得られるように以下としました。
| numberOfTrees | 100 |
| subSampleSize | 64 |
| timeDecay | 100 |
| shingleSize | 1 |
RANDOM_CUT_FOREST 関数やパラメーターの意味については、下記の AWS ドキュメントとリファレンスをご確認ください。
- 例: ストリーム上のデータ異常の検出 (RANDOM_CUT_FOREST 関数) – Amazon Kinesis Data Analytics for SQL Applications 開発者ガイド
- RANDOM_CUT_FOREST – Amazon Kinesis Data Analytics
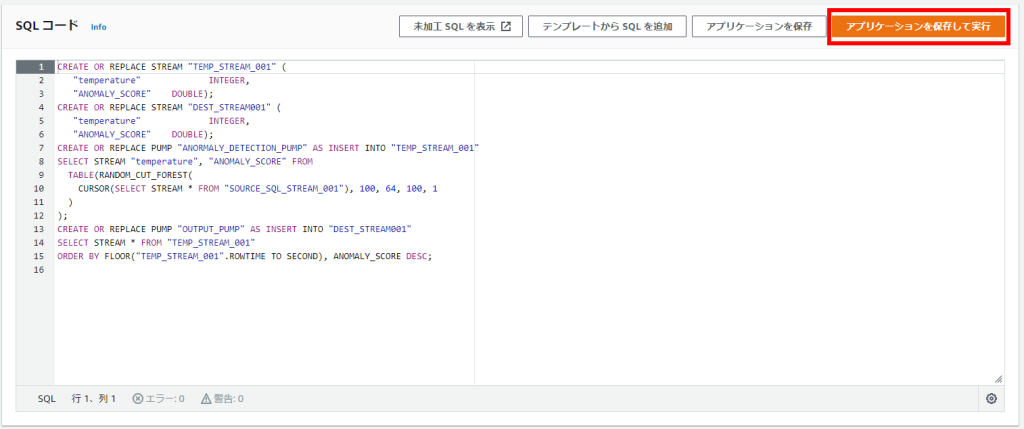
今回のSQL文は上記のサンプルを元に作りました。`temperature` に対して異常値スコア(anormaly score) を算出します。
CREATE OR REPLACE STREAM "TEMP_STREAM_001" (
"temperature" INTEGER,
"ANOMALY_SCORE" DOUBLE);
CREATE OR REPLACE STREAM "DEST_STREAM001" (
"temperature" INTEGER,
"ANOMALY_SCORE" DOUBLE);
CREATE OR REPLACE PUMP "ANORMALY_DETECTION_PUMP" AS INSERT INTO "TEMP_STREAM_001"
SELECT STREAM "temperature", "ANOMALY_SCORE" FROM
TABLE(RANDOM_CUT_FOREST(
CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"), 100, 64, 100, 1
)
);
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS INSERT INTO "DEST_STREAM001"
SELECT STREAM * FROM "TEMP_STREAM_001"
ORDER BY FLOOR("TEMP_STREAM_001".ROWTIME TO SECOND), ANOMALY_SCORE DESC;
「アプリケーションを保存して実行」すると分析結果が送信先へ配信されます。
結果
実際にサンプルのデータを SORACOM Funnel へ流してみます。24 ~ 26 度の水温が測定されることを想定して、何度かデータを送信します。
{"temperature":24}
{"temperature":25}
{"temperature":24}
{"temperature":26}
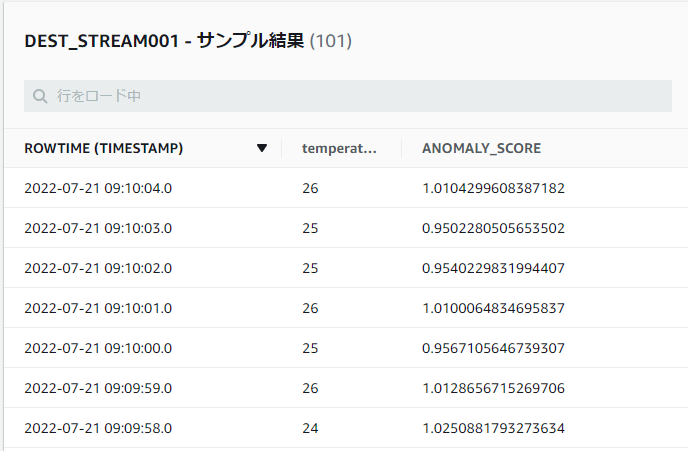
SORACOM Funnel へ上記のようなデータを流すと、Analytics 側でサンプル結果をプレビューできます。初めの数件のanormaly score は 0 として出力されます。これは、比較対象となる学習データが無いためです。今回の設定では 100 レコードを超えると算出されます。以下の画面では anormaly score が 1 ± 0.15 程度で算出されていることがわかります。
ヒーターの故障や外気の流入などなんらかの原因で、突然高い水温が測定されたと想定して30度のデータを流します。
{"temperature":30}
すると高い anormaly score が算出されました。今回 Lambda では 1.5 以上を通知するようにしているので、これが Slackへ通知されました。

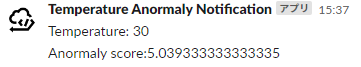
Amazon Kinesis Data Analytics 以外の設定については?
Amazon Kinesis Data Analytics を中心に解説しましたが、アーキテクチャーで紹介したその他のサービスの設定方法についてもリンクをご紹介します。
- SORACOM Arc について
- SORACOM Funnel について
- Amazon Kinesis Data Streamsについて
- AWS Lambda について
- Amazon Kinesis Data Firehoseについて
- Slack Incoming Webhook について
まとめ
SORACOM Funnel から データを送信し、Amazon Kinesis Data Analytics を利用して異常検知ができました。
今回はパソコンとSORACOM Arcを利用して疑似的なセンサーデータを送信しましたが、 これをそのまま Raspberry Pi に置き換えることもできるでしょう。今後、実際のセンサーからデータを収集する頻度に合わせたハイパーパラメータの検討や、AWS IoT Core Device shadow やなんらかのダッシュボードを利用するなどの通知部分の構成のさらなるブラッシュアップをして、アクアリウムの IoT 化を進めたいと思います。
― ソラコム峰 (mike)