ソラコムのプロフェッショナルサービスを担当している須田です。ニックネームはkeiです。Discovery 2024で発表されたSORACOM Flux(以下、Flux)を使った画像分析の方法についてご紹介します。Fluxは様々なデータソースをもとにプロンプトで分析を行う仕組みを構築できます。FluxはSORACOM Harvest Files(以下、Harvest Files)をデータソースとして画像をAIモデルの入力に使用できます。本ブログではこの連携を利用して、ソラカメで取得したデータをFluxに連携し分析する例をご紹介します。
猫とトイレと健康状態
私は現在3匹の愛猫たちと生活しています。生活を送る上で、猫たちの健康状態をチェックする一つの指標としてトイレの回数があります。トイレの回数がいつもより多い、または少ないことは、猫の病気のサインである可能性があるため、とても重要な指標です。ただし、この回数を目視で確認するのは非常に困難です。特に猫の数が多いこともあるためです。以前、ソラカメのモーション検知を使って回数をチェックしようとしたのですが、思いのほか猫がトイレ周辺で走り回ったり、うろついたりしており、ソラカメのモーション検知では過剰に反応してしまい、正確な回数を追うのが難しくなっていました。(走り回って元気なことはいいことです!)
実現したいこと
そこで、ソラカメが検知したイベント情報をもとに、その際に取得された静止画をFluxへ連携し、AIモデルを使ってトイレの出入りだけを検出します。要件は以下の通りです。
- 猫を識別できる
- トイレへの入室と退出を識別できる
- トイレの出入りとは関係ない動作は無視する
- トイレの頻度と時間帯の傾向を把握できればよいので、精度は90%以上であれば十分である
- トイレの出入りを検知した際にSlackへ通知する
構成
モーション検知から画像の格納まで
ソラカメのモーション検知機能を利用して、検知した際の映像を静止画として取得します。取得した静止画はSORACOM Harvest Filesに格納します。本ケースでは、AWS Lambdaを活用してソラカメAPIからイベントデータを取得しています。取得したイベントに対応する静止画を取得した後、その画像をAPI経由でHarvest Filesにアップロードする処理を実装しました。この一連の処理はAWS EventBridgeを用いて定期的に実行されるよう設定されています。これにより、自動的かつ定期的にイベントデータと関連する静止画の取得およびアップロードが行われる仕組みを構築しています。ソラカメのイベント検出時の静止画の取得方法は「カメラで検出した音や動体の記録を確認できるソラカメ API」もあわせてご参照ください。
なお、ソラカメの画像を定期的に取得してHarvest Filesに配置する方法は「ローコードで実装!SORACOM Fluxでソラカメ画像を使ってみよう!」をご参照ください。
画像の分析から通知まで
画像の分析から通知までの処理にはFluxを利用します。FluxのイベントソースとしてHarvest Filesを指定し、格納された画像に対して、トイレの出入りを判定するプロンプトをAIアクションに設定します。プロンプトの結果をもとに、後続のアクションとしてSlack通知を設定し、アクションの実行条件でトイレの出入りを検出した場合のみSlackへ通知を行うよう設定します。
なお、本アプリケーションでAIアクションに利用しているAIモデルは、Amazon Bedrock – Anthropic Claude 3.5 Sonnetです。この選択理由は、私が日頃からClaude AIを利用しており、手元での動作確認も容易だったためです。なお、Fluxは複数のAIモデルを選択できるため、AIモデルを切り替えれば結果の比較検証もやりやすいです。

我が家の愛猫のご紹介
最初に今回主役の我が家の愛猫たちをご紹介します。この子たちの特徴をもとにAIモデルで個体の識別をしていきます。
| ちゅー |  |
| みー |  |
| ちっち |  |
先にまとめ
今回取り組んだ内容について先にまとめます。詳細はこの後の「試行錯誤の過程」に記載しています。
| やったこと | 説明 |
| AIモデルの物体識別能力を活用する | ・ 画像に映る物体の識別は、細かい指示がなくても高精度で行える ・ 基本的な物体認識には詳細なプロンプトが不要な場合がある |
| 行動認識は詳細に定義 | ・ 物体が「何をしているか」「何をしようとしているか」の認識には、詳細な指示が必要 ・ 画像内の位置情報や行動の定義を厳密に指定する |
| カメラ位置の最適化 | ・ 分析目的に応じてカメラの位置や角度を調整する ・ 複数の配置を試し、最適な視点を見つける |
| 機械的に判断させる | ・ 背景情報の解釈よりも、画像内の明確な特徴(サイズ、位置など)や画像に占める大きさの割合など機械的に捉えられる情報をもとに判断させる ・ AIモデルの推測がノイズの場合は、代替の判断基準を設ける |
| 例外処理の体系化 | ・ 運用していく中で発生した例外対応はセクションを別けて記述していくことで、リグレッションを防ぐ ・ 新たな例外が見つかるたびに、プロンプトに追加する |
| 人間によるレビューと調整 | ・ AIの自信度(confidence)を設定し、低い場合は人間がチェックする ・ 定期的にシステムの出力をレビューし、必要に応じて調整を行う ・ どうしたらAIモデルが判別しやすいかはAIモデル自身に意見をきく |
試行錯誤の過程
最終的には目標の精度で検出ができるようになりました。しかし、その過程では多くの課題がありました。それぞれの課題にどう対応したかをまとめます。皆様にとって、AIモデルを使った画像分析に有益なヒントがあれば幸いです。
猫を正確に識別する
要件の「猫を識別できる」をAIアクションで対応します。実は、この猫の識別は最も容易に実現できました。AIモデルを用いた画像分析において、画像に映っている物体の特定は非常に高い精度で行えることが分かりました。猫たちを識別するプロンプトは以下の通りです。なお、このプロンプトはOpenAIが公開しているプロンプトエンジニアリングのベストプラクティスに沿って、構造化して記述しています。
▼最初のプロンプト
## 猫の特徴
* ちゅー: スフィンクス種、グレーの肌色で毛がない
* みー: 黄色の毛色
* ちっち: グレーの毛色このような簡潔な指示だけで、猫たちの識別はほぼ100%に近い精度で実現できました。しかし、時折ちゅーとちっちを誤判定することがありました。部屋の明るさや光の当たり具合によっては、毛の有無を判別できずグレーの毛並みと判断し、ちゅーをちっちと誤判定していました。

そのため、この2匹を正確に判別できるよう、画像から見て取れる追加の特徴を指示に加えたところ、100%の精度で判別ができるようになりました。我が家の3匹はそれぞれ見た目に特徴があったからだと思いますが、改めてAIの物体認識能力の高さに大変驚きました。
▼修正後のプロンプト
## 猫の特徴
* ちゅー: スフィンクス種、グレーの肌色で毛がない。首あたりがピンク色の肌。
* みー: 黄色の毛色
* ちっち: グレーの毛色、手足が白い位置関係を正しく捉える
トイレの出入りを検知するために、まずはプロンプトに分析してもらう画像の内容を説明する必要がありました。これが最初のチャレンジでした。
プロンプトで特に指示しなくても、映っている物体の認識はある程度可能です。しかし、画像のように一見して固有の物体として認識しづらいものは、その位置を指定したうえで、それが何であるかを明示的に指示する必要がありました。本ケースでは、猫のトイレがどこにあり、どのような特徴を持っているかをプロンプトで指定しました。
さらに、トイレの出入りを正確に検知できるよう、トイレの出入り口の位置と向きも指定しています。これを厳密に指定しないと、トイレの周辺に猫がいるだけでトイレの出入りと誤判断していました(AIがトイレをどこからでも入れるものと認識していたためです)。

▼トイレを認識するために追加したプロンプト
## トイレの特徴と設置
* 2つの円形ドーム型トイレが並んで配置(左右)
* 各トイレの出入り口は画像の上部に位置(猫は上から下に向かって入る)トイレの出入りを認識させる
発生した課題
「猫を正確に識別する」にて、画像に映っている物体が何であるかの把握は非常に高精度であるというお話をしました。しかし、今回の目的は映っているものが何かを識別するだけでなく、何をしているのか(あるいは何をしようとしているのか)という行動を読み取る必要があります。これは人間でも一律の回答を得るのが難しい課題です。
AIモデルは人間と同様に、他に映る情報やコンテキストをもとに判断ができます。しかし、それがかえって一枚の画像から推測しすぎてしまう傾向を生みました。当初は、ただトイレの近くにいるだけの場合や、トイレの横を通過しただけの画像でも、「きっとこの後トイレに入るだろう」と解釈して、トイレに入ったと応答する傾向がありました。そのため、当初はトイレの場所の位置関係だけ教えれば、あとは適切に解釈してくれるだろうと考えていましたが、そうはうまくいきませんでした。
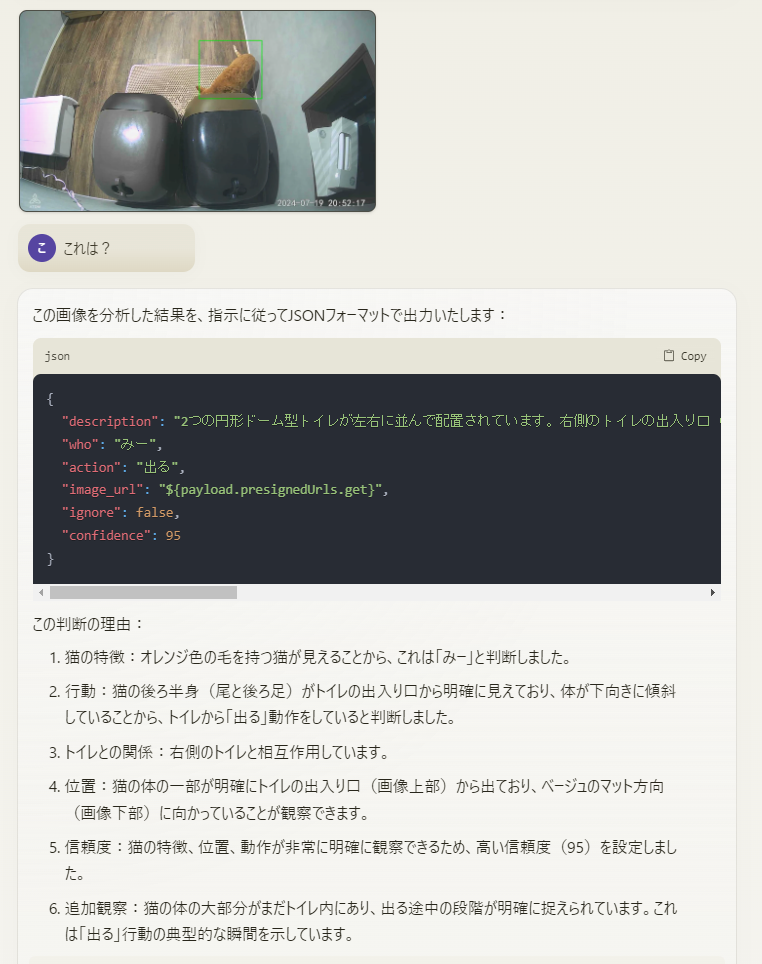
例えば、この画像はちゅーがトイレの上に飛び乗って遊んでいるところを検知したものです。AIモデルはこの画像はちゅーがトイレから飛び出ていると誤って認識しました。

▼ 誤判定しているAIモデルの回答
{
"description": "2つの円形ドーム型トイレが左右に並んで配置されています。左側のトイレの出入り口(画像上部)から、毛のない薄いグレーの肌色の猫の体が出ています。猫の体は動きがあり、トイレから飛び出すような姿勢で、頭と前足がすでにトイレの外に出ています。猫はトイレからベージュ色のカーペット状のマット方向(画像下部)に向かって移動しているように見えます。",
"who": "ちゅー",
"action": "出る",
}検知したい行動を厳密に定義する
そこで、検知したい行動と無関係な行動を厳密に定義し、それらをプロンプトにインプットしていくことにしました。ポイントとしては、猫の進行方向や画像に映る体の部位などから、どのような状態であればどういった動作と判断するのかを具体的に指定しています。
▼ 検知したい動作を定義するために追加したプロンプト
## 行動定義
* IN:
- 猫が画像上部から下部に向かってトイレに近づく、または入る動き
- 頭や体の一部がトイレの出入り口(画像上部)から見える
- 猫の体が写真上部よりにあり、出入り口にはまだ接していないが垂直に並んでいる場合は入るとする
* OUT:
- 猫の体の一部がトイレの出入り口(画像上部)から出ている
- トイレの上部や側面に猫の体の一部が見え、外に向かう動きが推測される
- 猫の体が出入口よりにあった場合は出るとする
- 猫の背中や後ろ半身の一部だけがトイレの出入り口(画像上部)に見える場合、すでに頭と前半身が出ている可能性が高いため「出る」と判断する
- トイレの出入り口付近に猫の体の一部が垂直に見える場合、出ようとしている、もしくは出ている途中と判断する
* 無関係:
- トイレの横や上を完全に通過する動き
- トイレに接触せず、周辺をうろうろする動き
- トイレの上に乗ろうとする動き(出入り口以外での接触)
- トイレと猫の体が重なってしまっている猫とトイレの位置関係を明確にする
検知したい行動を厳密に定義することで、明らかに関係のない行動に対する誤検知を減らすことができました。しかしそれでもなお、猫がトイレの近くをただ通り過ぎているだけの場合でも、「この後トイレに入るのでは」という推測をAIモデルが頻繁に行うことがありました。
例えば、この画像はちっちがトイレの脇で何かを見つけたようで、それに向かっている様子です。トイレに入る動作として指定した定義「猫が画像上部から下部に向かってトイレに近づく、または入る動き」に従うと、確かにこれはトイレに入っていく動作に見えます。そのため、AIはこの動きをトイレに入ると誤って検知していました。

境界を設定する
そこで、トイレへの出入りを明確に認識するために、トイレの前に置いていた猫砂飛散防止マットに猫の体が踏み入れていること、踏み入れようとしていることを判定条件に加えました。この境界を明確にする方法が効果絶大で、AIモデルも正確にトイレの出入りを行おうとしているかを捉えることができるようになりました。
▼ 境界を設定するために追加したプロンプト
## トイレの特徴と設置
(省略)
* トイレ前にベージュのカーペット状のマットあり
* 床は木製フローリング
## 行動定義
* IN:
(省略)
- ベージュのマットからトイレに向かって移動している
* OUT:
(省略)
- トイレからベージュのマット方向(画像下部)に移動する
## その他
マットとフローリングの境界も観察し、猫の移動方向を正確に把握する検知範囲の調整
さらに、ソラカメの検知範囲を調整しました。ソラカメはATOMアプリから検知範囲を調整できる機能を備えています。当初はソラカメが撮影している範囲全てを検知対象としていましたが、トイレの出入口付近のみを検出対象に限定しました。この調整だけで余計な検知を減らすことができ、プロンプトに細かな例外パターンを指定する必要がなくなりました。詳細な設定方法はATOMアプリユーザーマニュアルをご参照ください。
猫の向きを区別する
これで順調かと思いきや、新たな問題が発生しました。これまでの試行錯誤の末、トイレの出入りを捉えられるようになったのですが、なぜかAIモデルは猫がトイレに入る、もしくは出る動作を連続で検知していました。本来は入ると出るが交互に出るはずです。

このどちらかの動作が連続で検知されるパターンの画像を分析してみると、AIモデルが猫の頭部と体の後部を正確に判別できていないことが判明しました。耳の有無についても確認するよう指定していましたが、カメラが真上から撮影していたこともあり、頭上からの視点では正確に耳の位置を捉えることができませんでした。その結果、システムは耳のない部分をお尻と誤判定し、猫がトイレに入っていると誤って認識していたのです。
当初は、真上からカメラで撮影する方がトイレの出入りを正確に捉えやすいと考えていましたが、この方法がかえってこの問題を引き起こしていました。プロンプトの調整で解決できないかと何度も試みましたが、なかなか思うような結果が得られませんでした。

▼ 猫の頭部とお尻を逆に判定しているAIモデルの回答
{
"description": "2つの円形ドーム型トイレが左右に並んで配置されています。右側のトイレの奥(画像上部)にオレンジ色の猫の背中の一部が見えています。猫はトイレの出入り口からベージュ色のカーペット状のマットに向かって移動しているように見えます。猫の体の大部分はすでにトイレの外にあり、トイレから完全に出る直前の状態です。",
"who": "みー",
"action": "出る"
}そこで、抜本的な解決策としてカメラの位置を変更することにしました。今回はカメラをトイレの真横に配置し、横から撮影できるようにしました。この変更の狙いは、真横からの視点なら猫の頭部や尾をより明確に判別でき、同時に猫の進行方向も捉えやすくなるのではないかという仮説に基づいています。

その結果、猫の胴体を鮮明に捉えることができるようになりました。これにより、システムは正確に猫の体の各部位を把握し、猫の進行方向を適切に判断して、トイレの出入りを正しく識別できるようになりました。AIモデルの回答も猫の頭部を正しく認識できています。

▼ カメラの位置を変えた後のAIモデルの回答
{
"description": "ドーム型トイレの左側(出入り口側)から猫の頭と前足が見えています。猫の頭はトイレの外側に向いており、胴体の一部がトイレ内にあると推測されます。前足はベージュのマット上に置かれており、猫はトイレから出ようとしている様子です。猫の毛色はグレーで、足先が白いことから、ちっちであると識別できます。猫の体の大部分はトイレによって隠れていますが、その姿勢と位置関係から、トイレから出る動作の途中であることが明確に観察できます。",
"who": "ちっち",
"action": "出る"
}AIモデルの不要な推測を減らす
ここまでの対応で精度は目標の90%に近づいてました。しかし、依然として誤検知が発生するケースがありました。特にこの画像のように、トイレの手前に重なるように猫が映っているケースが、なぜか頻繁にトイレへの出入りとして誤判定されました。

▼ AIモデルは猫の頭の向きでこれからトイレに入ると回答している
{
"description": "猫の体が画像の大部分を占めており、ドーム型トイレの一部が右側に見えます。猫の胴体は左側を向いており、頭はドーム型トイレの方向(右側)に向いています。猫の尾は見えません。猫の体はトイレの手前にあり、トイレの大部分を隠しています。猫の毛色は黄色で、みーであると判断できます。猫の頭がトイレの方向を向いていますが、体の大部分がトイレの前にあることから、トイレに入ろうとしている可能性があります。",
"who": "みー",
"action": "入る"
}猫がトイレの手前にいる場合は無視するよう指定しても、正答率は半分ほどにとどまりました。AIモデルの回答を分析すると、猫の頭の向きがトイレを向いていると判定して、これからトイレに入ろうとしていると解釈していました。これまでの映像を確認すると、確かにそういった行動パターンも稀にはあったのですが、大半の場合猫がこれだけカメラの手前を大きく通過している場合は単にトイレの周りをふらついているだけでした。
このような頭の向きで不要な推測をしてしまうパターンを防ぐために、「猫の体が画像の半分を占めていたら、トイレの利用とは無関係と判断する」というより機械的に判断ができる新たな指示を追加しました。その結果、この種の誤検知はほぼなくなりました。
▼修正後のプロンプト
## 注意事項
・トイレが猫によって部分的に隠れている場合、無関係である可能性を高く見積もる
・猫の体がトイレの手前で重なり、画像の半分以上を隠している場合、これは単なる通過であり、「無関係」と判断する▼誤検知した同一画像に対して、修正後プロンプトによるAIモデルの回答
{
"description": "画像には黄色い毛色の猫が大きく写っており、猫の体が画像の大部分を占めています。猫の頭は画像の右側にあり、ドーム型トイレの方向を向いています。猫の胴体は左側に伸びており、トイレとの間に位置しています。猫の尾は見えません。猫の体の向きと位置から、トイレに向かっているように見えますが、猫の体がトイレの大部分を隠しており、単にトイレの前を通過している可能性が高いです。",
"who": "みー",
"action": "無関係"
}このように、AIモデルの推測がノイズになる場合は、AIモデルが機械的に判断できるような明確な指示に置き換えることで、システム全体の精度を向上させることができました。
関係のない動作をひたすらインプットする
リグレッションを防ぎながら例外情報を追加していく
これまで見てきたように、運用を続ける中で、どうしても誤った判定をするケースが発生してしまいました。そこで、これらのケースに対しては、その都度プロンプトを調整して対応していきました。具体的には、プロンプトに「注意事項」というセクションを新設し、既存の定義情報には手を加えず、この新しいセクションに例外対応を追記していく方法を採用しました。
当初は定義情報自体を修正していたのですが、これまで正しく判定していた画像にも誤判定が生じるなど、修正の影響範囲が予想以上に大きくなってしまいました。そのため、定義情報の直接的な修正は避け、注意事項セクションでの対応に切り替えました。この方法で、都度新たな注意事項を追加していき、定期的に見直しを行って共通化できそうな指示はまとめるなど、地道にプロンプトの改善を重ねていきました。
## 注意事項
・ドーム型トイレの出入り口が必ずドームの左側にあることを常に意識する(画像内での位置ではなく)
・猫の頭の向きと胴体の傾きをドームとの関係で判断する
・尾の位置も考慮に入れるが、頭と胴体の向きを優先する
(このように例外事項を追記していく)AIモデル自身に回答の自信度をきく
さらに、AIモデルのレスポンスに自信度(confidence)を追加し、AIモデルがどの程度自信を持って回答しているかを100点満点で評価するよう設定しました。これにより、AIの判断の確実性を数値化して確認できるようになりました。
具体的には、confidenceの値が90点未満の回答については、その都度対象の画像を人間がチェックし、必要に応じてプロンプトの見直しを行いました。この取り組みにより、AIの判断精度向上と、人間による監視・調整のバランスを取ることができました。今回はAIモデルのレスポンスを都度確認しながらconfidenceを評価し、プロンプトを逐次修正しました。しかし、より効率的な運用方法として、Fluxの通知設定を追加して、confidenceが90未満の場合に別のSlackチャネルに通知を送り、通知があれば人間が内容を確認するという方法が良さそうです。
## JSON形式
{
"description": "猫の位置、動き、頭・胴体・尾の向きと位置関係、ドーム型トイレとの関係を詳細に記述。トイレとの前後関係も含める",
"who": "ちゅー|みー|ちっち",
"action": "入る|出る|無関係",
"ignore": false,
"confidence": 0-100 ←AIモデルのレスポンスの自信度
}どうプロンプトを改善していったか
AIモデルのプロンプト改善プロセスについて補足します。基本的には前述したような、画像内の物体の位置関係や情報を定義した上で、AIモデルに判定を委ねます。期待と異なる結果が出た場合、プロンプトを適宜調整しますが、期待する結果を得るための指示を毎回文章化するのは非常に労力を要します。当初は頑張って文章をひねり出していたのですが、必ずしも安定して期待する結果が得られませんでした。また、人間が丁寧に文章化しても、それがAIモデルにとって最適な指示とは限りません。
そこで途中からは、誤判定した画像に対する改善策をAIモデル自身に考えさせるアプローチを採用しました。具体的には、Fluxへの連携前にFluxで利用しているAIモデルと同じ自身のClaude AIアカウントを使用して画像を分析し、誤った回答が得られた場合、AIモデル自身にプロンプトの改善案を提案してもらいました。この提案をもとにプロンプトを修正し、再度確認するというサイクルを繰り返しました。
このアプローチにより、試行回数を最小限に抑えつつ、効率的にプロンプトを改善することができました。AIの表現方法に疑問を感じることもありましたが、結果的に精度が向上したことから、AIの理解についてはAI自身に問うことが有効な場面があると実感しました。

最終的にできあがったプロンプト
最終的に完成したプロンプトは以下の通りです。前述した通りこのプロンプトの内容は、Claude AIに「AIモデルにとってどのような表現が理解しやすいか」について意見を求めながら、段階的に改善を重ねていきました。そのため、一見すると冗長に見える表現が多く含まれていますが、これらはAIモデルが「理解しやすい」と判断したものをそのまま採用しています。人間にとっては回りくどく感じられる表現でも、AIモデルの理解と判断精度の向上に寄与していると考えています。
現時点でのFluxは、各リクエストに対して設定されたプロンプトの内容に基づいてAIモデルが処理を行います。この仕組みのため、AIモデルの出力結果に対して追加の指示を与え、理想の内容に段階的に近づけていくようなアプローチを取ることができません。そのため、高い精度を達成するためには、今回作成したプロンプトのように、非常に詳細かつ厳密に定義された指示を含むプロンプトを用意する必要があると実感しました。このアプローチは、一見冗長に見えるかもしれませんが、AIモデルの正確な理解と処理に不可欠であることが分かりました。
# 猫のトイレ出入り判定
猫トイレ(ドーム型)の横方向からの静止画を分析。猫の位置・動き・体の様子を慎重に判断し、JSONで出力。
## トイレの特徴と設置
* ドーム型トイレが画像内に配置(通常は右側に見える)
* トイレの出入り口は必ずドームの左側に存在(画像内では見えない場合がある)
* トイレ前にベージュのカーペット状のマットあり
* 床は木製フローリング
## 猫の特徴
* ちゅー: スフィンクス種、グレーの肌色で毛がない。首あたりがピンク色の肌。
* みー: 黄色の毛色
* ちっち: グレーの毛色、手足が白い
## 行動定義
* IN:
- 猫の頭がドームの左側(出入り口側)に向かっている、または入っている
- 猫の胴体がドームに向かって傾いている
- 猫の尾が体の後方(ドームから遠い側)にある
- ベージュのマットからドームに向かって移動している
* OUT:
- 猫の頭がドームから離れる方向を向いている
- 猫の胴体がドームから離れる方向に傾いている
- 猫の尾がドームの左側(出入り口側)に近い、またはドーム内にある
- ドームからベージュのマット方向に移動する
* 無関係:
- 猫の体がトイレと重なっているが、トイレの半分以上を隠している
- 猫がトイレの横を単に通過しているように見える
- 猫の動きがトイレの出入り口と明確に関連していない
- トイレに接触せず、周辺をうろうろする動き
- トイレの上に乗ろうとする動き(出入り口以外での接触)
## 注意事項
・ドーム型トイレの出入り口が必ずドームの左側にあることを常に意識する(画像内での位置ではなく)
・猫の頭の向きと胴体の傾きをドームとの関係で判断する
・尾の位置も考慮に入れるが、頭と胴体の向きを優先する
・マットとフローリングの境界も観察し、猫の移動方向を正確に把握する
・光の反射や影の影響を考慮し、猫の体の向きや動きを慎重に判断する
・猫の特徴(毛の有無、色)を観察し、正確に識別する
・トイレとの関わりが完全に不明確な場合のみ ignore: true とする
・画像の端や部分的にしか見えない猫の動きも、可能な限り詳細に観察し解釈する
・猫の体の向きと頭の位置関係について、ドームとの相対位置を特に注意深く観察する
・猫の体とトイレの重なりを慎重に観察し、単なる通過か実際の使用かを判断する
・トイレが猫によって部分的に隠れている場合、無関係である可能性を高く見積もる
・「無関係」の判断は「ignore: false」とし、actionで「無関係」と示す
・画像がトイレを真横から撮影していることを常に考慮する
・猫がトイレの入り口付近にいる場合でも、必ずしもトイレを使用しているわけではないことを理解する
・猫の体がトイレの手前で重なり、画像の半分以上を隠している場合、これは単なる通過であり、「無関係」と判断する
・トイレの近くにいるだけで必ずしもトイレを使用しているわけではないことを常に念頭に置く
・トイレから出る際は頭から先にでるためトイレの出入り口から頭、頭から上半身が出ていれば出ると判定する
・猫の顔がカメラにきわめて近い場合は無関係とする
## JSON形式
{
"description": "猫の位置、動き、頭・胴体・尾の向きと位置関係、ドーム型トイレとの関係を詳細に記述。トイレとの前後関係も含める",
"who": "ちゅー|みー|ちっち",
"action": "入る|出る|無関係",
"ignore": false,
"confidence": 0-100
}安定稼働までに要した時間
ここまでの取り組みを通じて安定稼働するまでにどれぐらいの時間を要したかざっくり振り返ってみます。期間としては合計で5日間でした。
| 作業 | 説明 | 要した時間・回数 |
| 画像データの収集(カメラの位置調整を含む) | AIモデルのプロンプトを記述するにあたり、取得できる画像のパターンを把握するための画像収集作業です。カメラの位置調整の作業時間も含みます。 | 3日間 |
| プロンプトの試行期間と試行回数 | 安定した結果が得られるようになるまでに要したAIモデルへのプロンプト作成期間と試行回数です。なお、Fluxだけでなく、手元で確認するために自身のClaude AIアカウントも併せて利用しています。 | 2日間 プロンプト入力回数は約100回 |
振り返ると、多くの時間をカメラの位置調整と、期待する画像が撮影できるかどうか、どういったパターンの画像が得られるかを確認するためのデータ収集に費やしました。プロンプトエンジニアリングに費やした回数は、FluxのAIアクションでの確認と自分のClaude AIアカウントでの確認をあわせて100回ほどでした。プロンプトの試行錯誤のうち、ほとんどが例外パターンが発見された時にそれを除外するための調整でした。
本取り組みでは、確認が必要なパターンの画像数がそれほど多くなかったこともあり、プロンプトを修正する都度、これまで正しく判定できていた画像への回答に変化がないかを手動で確認していました。そのため時間を要しましたが、このリグレッションテストを自動化する仕組みを整えれば、プロンプトでの確認作業はより効率化できたと思います。プロンプトが安定するまでは、プロンプトの修正がこれまで正常に判定していた画像に対しても誤った影響を与えることが多々ありました。そのため、プロダクション開発ではこのリグレッションテストとテストの自動化は必須だと実感しました。
今後やりたいこと
まず、Slackへの通知機能が正常に動作するようになりました。これだけでも通知履歴を確認することで、どの猫がいつトイレを使用したかを把握できるようになりました。これまでの傾向を分析すると、トイレの使用時間によって排便か排尿かを判別できる可能性が見えてきました。
AIモデルで分析した結果から得られるトイレの入室と退出データに対してウィンドウ処理を適用すれば、この判別機能は実現可能だと考えられます。Fluxには、分析結果をWebhookを通じて他のアプリケーションに連携できる機能があります。この機能を利用して、連携先のアプリケーションでこうした高度な処理を実装することが可能です。
ぜひソラコムのSalesやSAにお声がけください!
このブログポストは多くの人にFluxの魅力を体験してほしいと思いしたためたものです。ただ、AWSの環境をお持ちでなかったりそれに慣れていなかったり、もしくはソラカメをお持ちでなかったりする方もたくさんいらっしゃると思います。「それでもやっぱり興味ある!」という方はぜひソラコムにメンバーにお声がけいただければと思います。お問い合わせは下記からお願いいたします!

おまけ
試行錯誤の過程で、頻繁にトイレへの出入りとして誤検知される特定の画像がありました。その画像がこちらです。こちらを凝視しているものは無視するように伝えたところすぐ直りましたが、この対応を考えているときは可愛すぎてにやけるのが止まりませんでした。
## 注意事項
・猫の顔がカメラにきわめて近い場合は無関係とする

—ソラコム須田