対話で画像認識
こんにちは。SORACOM Cloud Camera Service(通称ソラカメ)エンジニアの五十嵐(ニックネーム: Ash)です。お陰様で多くのお客様に、遠隔監視を簡単に実現するソリューションとしてソラカメを採用いただいております(事例一覧)。現場に移動せずに、リモートでの監視ができるようになると一人で扱える現場の数が急増するので、人に代わって、自動で画像をチェックするという機能が求められてきます。

そこで、今注目されているのが、生成 AIを用いた画像認識(解析)です。これまでの画像認識は、何枚もの画像を人の手によってラベリングして、機械学習のモデルを構築するやり方が一般的でした。しかし、画像認識に生成 AI を利用すると、モデルを作成せずに、生成 AI に「この画像には何人映ってますか?また、立っている人、座っている人に分類して下さい?」といった質問をすると、「画像には3人が映っており、2人は立っていて1人は座っています。」と回答してもらえるようになります。これまで生成 AI を利用した画像認識の際に問題となっていたコストについても、技術の進歩により、ソラコムのサービスにおいて、従来の 1/50 以下( 0.3円/枚 程度:画像認識部分のみ)で画像認識を行うことが可能になりました。このブログでは、身近な課題や、お客様の要望の高かった8種類の画像認識に生成 AI を用いて、その認識精度の高さを利用したプロンプトと共に掲載します。
画像認識というと複雑なシステムを想像されると思いますが、ソラコムのサービスを利用することによって、システムを簡単に構築できるので、最後に紹介するシステムの構築方法を参考に皆様も是非画像認識にチャレンジしてみてください。

今回の8種類の画像認識
生成 AI による画像認識
生成 AI を利用して画像認識を行う場合、生成 AI に対して何を認識して欲しいのかを「プロンプト」を用いて指示をする必要があります。生成 AI が理解しやすい様なプロンプトを用意することで、性能が大きく改善することが知られており、生成 AI と何度も対話をして、良いプロンプトを作成する過程を「プロンプトエンジニアリング」と呼び、様々な方法が提案されています。今回のプロンプトは次の様な方針で作成しました。
- 最大限の性能を得るために、英語を利用
- データを可視化するため、認識結果に JSON を指定
- 混雑度などは予め例を提示(one shot prompting)
画像の認識結果
部屋の散らかり具合
「部屋片付けた?」。「うん。きれいにしたよ。」という会話をへて、いざ部屋に行ってみると何度も気絶しそうになったことがあります。その時に「きれいになってないじゃん。」と言うと、「いやきれいじゃん。それはダダの意見ですよね。」と言い返されてしまうので、ダダの感じる部屋が整頓された状態を娘達に伝えるために、散らかり具合を数値化することを試みました。ソラコムでも倉庫や会議室の整頓状態を定期的に検査しているので、職場でも利用可能な画像認識だと思います。表1が今回利用したプロンプトになります。散らかり具合を数値化するために、それぞれの散らかり具合を定義しました(0 = 散乱したアイテムなし、25 = アイテムは通路の一側のみ、35 = アイテムは通路の一側にあり、通路に少しはみ出している、50 = 通路の両側にアイテムがある、75 = 周囲に多くのアイテムがあるが、人はまだ通行可能、100 = 人が通行できないほど散乱している)。また、それぞれが段ボールなどにしまわれている場合は、意図した状態なので、その状態がわかるようにフラグ(“tidy” : 1)を設定しています。同様に通路が塞がれてしまっている状態を検出するフラグ(“block_alert” : 1)も設定しました。
表1: 部屋の散らかり具合に利用したプロンプト
| プロンプト | プロンプトの日本語訳 |
You are analyzing a photo of a hallway. Based on the image, return the result in the following JSON format:{Field Definitions: - "recognition" : a fixed string "mess_detection" to label the recognition.Return only the JSON. Do not include any extra commentary or formatting. | あなたは廊下の写真を分析している。画像に基づいて、以下の JSON 形式で結果を返してください。{フィールドの定義: - "recognition" : 解析をラベル付けるための固定文字列 "mess_detection"。JSON のみを返す。追加のコメントやフォーマットは含めない。 |
図1が認識結果になります。左の図では散らかり具合が35%「アイテムは通路の一側にあり、通路に少しはみ出している。」と判定されました。感覚的には35-50%の間くらいなので、そこそこの精度で数値化できている様です。また、図中に写っている掃除機、段ボール、スケートボード、ボール、ヘルメット、おもちゃなどほぼ全てを認識しています。次に真ん中の図ですが、全ての物をしっかりと箱の中に入れて、物はでているけど片付いている状態を模擬しました。結果として “tidy” : 1 となり、意図して物を出している状態を認識することができました。右の図では、通路を塞いだ状態を模擬しました。この状態では “block_alert” : 1 となり、通路が塞がっており、危険な状態であることを検出できました。散らかり具合は75%となり、感覚的には75-100%の間なので、正しく認識していると思われます。次回はこの数値を示して、少なくとも35%以下に保つ様に娘達にお願いしようと思います。

図1:部屋の散らかり具合の認識結果
ゴミの状態の判定
カラスによって、共用スペースのゴミが荒らされることもあり、ゴミの状態を監視するのは身近な問題でした。表2が今回利用したプロンプトになります。今回は、ゴミがしっかり出されている(ゴミ箱に入っているか、完全にネットに覆われているか)かを判定するフラグ(”garbage_covered_by_net_or_dustbin” : 1)、ゴミがはみ出ている場合のゴミの量(“overflowed_garbage_ratio”)、さらにカラス等によってゴミが荒らされていることを検出するフラグ(spilling_garbage_of_garbage_bag: 1)を設定しました。
表2: ゴミの状態に利用したプロンプト
| プロンプト | プロンプトの日本語訳 |
You are analyzing a photo of a garbage dumping area.Based on the image, return the result in the following JSON format:{Field Definitions: - "recognition" : a fixed string "garbage_check" to label the recognition.Return only the JSON. Do not include any extra commentary or formatting. | ごみ捨て場の写真を分析しています。画像に基づいて、以下の JSON 形式で結果を返してください。{ "description" : "文字列"フィールド定義: - "recognition" : 解析結果をラベル付けするための固定文字列 "garbage_check"。JSON のみを返す。追加のコメントやフォーマットは含めない。 |
図2が認識結果になります。左の図は、5%ほどネットの外にゴミがでている(“overflowed_garbage_ratio”:5 )ことをしっかりと検出しました。右の図では、30% 程度(“overflowed_garbage_ratio”:30)ゴミ箱からはみ出ていると認識されました。さらに、ゴミ袋が破られて、ゴミが散乱していることについてしっかりと認識しました(“spilling_garbage_of_garbage_bag”:1) 。これを利用することで、ゴミがしっかりと捨てられているか、カラスなどによってゴミが散乱していないかを正しく検出できそうです。

図2:ゴミの状態の認識結果
在庫状況
在庫状況の把握を自動化したいというお問い合わせが非常に多く、展示会等でデモ展示をしている人気の画像認識です。表3が利用したプロンプトになります。プロンプトでは、棚の大きさを考慮して、より正確に在庫率を取得するため、棚の相対的な大きさ(上段を1として、中段が2、下段が4)を指示しています。そして最終的な在庫率はそれぞれの棚の加重平均として算出するように指示しています。
表3: 在庫状況に利用したプロンプト
| プロンプト | プロンプトの日本語訳 |
| You are analyzing a photo of a three-tier wooden rack containing fruits. Estimate the percentage of visible space occupied by fruits on each shelf: top, middle, and bottom. Shelf Size Weighting (Relative Area): – Top shelf = 1 unit – Middle shelf = 2 units – Bottom shelf = 4 units Use the following formula to calculate the weighted average occupancy: Weighted average = (Top + 2 × Middle + 4 × Bottom) / 7 Return your results in the following JSON format: {Field Definitions: - "recognition" : a fixed string "fruit_occupancy" to label the recognition task.Return only the JSON. Do not include any extra commentary or formatting. | あなたは、果物が置かれた 3 段の木製ラックの写真を分析しています。 各棚(上段、中段、下段)で果物が占める可視領域の割合を推定してください。 棚のサイズ加重(相対面積): – 上段 = 1 単位 – 中段 = 2 単位 – 下段 = 4 単位 次の式を使用して、加重平均占有率を計算してください。 加重平均 = (上段 + 2 × 中段 + 4 × 下段) / 7結果を次の JSON 形式で返してください。 {フィールド定義: - "recognition" : 解析タスクをラベル付けするための固定文字列 "fruit_occupancy"。JSON のみを返す。追加のコメントやフォーマットは含めない。 |
図3が認識結果になります。左の図では、上段15、中段5%、下段20%となり、全体の在庫率が加重平均として16%(誤差は小数点の影響)と算出されました。真ん中の図の在庫率は57%、右の図は76%と認識されました。全体の真ん中と右の図の上段は同一の配置になって、真ん中の図の上段が70%、右の図の上段は75%となり、ほぼ同様の在庫率となっていることから、判定が一定の基準で行われていることが確認できます。 在庫率の正確性については、人の目でも判定が難しいですが、例えば右の図は100%に近いのに対して、76% となっているため、他の認識結果ほど、正確ではないものの、欠品などの検出には十分活用できるレベルに認識されました。

図3:在庫状況の認識結果
画像の認識結果の一覧
表4に認識に今回の認識に使った画像と認識結果のまとめを記載しました。全ての解析において、正確、もしくはほぼ正確な認識結果が得られ、生成 AI の認識精度の高さを感じられることができました。その他の画像認識に利用したプロンプトとその結果については、参考資料を参照して下さい。
表4: 認識させた画像とその結果
| 種別 | 画像 | 解析結果 |
| 部屋の散らかり具合 |  | ⭕️ 散らかっている物体(ボール、スケートボード、ぬいぐるみなど) ⭕️ 散らかり具合の数値 |
| ゴミの状態の判定 |  | ⭕️ ネットからはみ出ていないか ⭕️ カラス等によって、ゴミがネットの外に、散乱していないか |
| 在庫状況 |  | 🔺 どの程度棚棚が占有されているか(在庫率が若干低く出る) |
システム構成
この画像認識を実現するためのシステムの概要が図4になります。
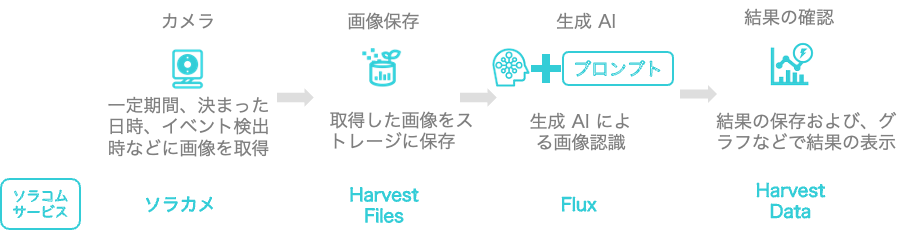
図4:システムの概要
このシステムは、ソラコムのサービスを用いて、簡単に構築することが可能です。表5にそれぞれの機能がどのソラコムサービスと対応しているのかを記載します。一度この構成でシステムを組むと、その後はプロンプのみを修正することによって、様々な画像認識に対応することが可能になります。今回は、画像認識を行う SORACOM Flux の設定と、結果を確認する SORACOM Harvest Data について簡単に記載しておきます(ソラカメを含む、全体の設定のについてはこちらのレシピを参考にしてください)。
表5: ソラコムのサービスとの対応
| 機能 | 対応するソラコムのサービス |
| カメラから画像を取得 | ソラカメ |
| 画像の保存 | SORACOM Harvest Files |
| 画像を生成 AI で解析 | SORACOM Flux |
| 結果の確認 | SORACOM Harvest Data |
SORACOM Flux の設定
SORACOM Flux を用いて、図5の様なフローを作成します。今回はカメラ画像の取得と画像の認識の2つのフローを設定します。
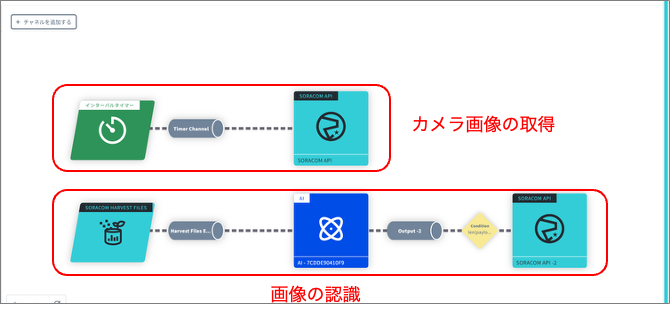
図5:SORACOM Flux の設定
カメラ画像の取得のフロー
最初にカメラ画像取得のフローについて説明します。SORACOM Flux では、最初にチャネルと呼ばれる、入力を作成する必要があります。図6で示す部分が、カメラ画像を取得するチャネルの画面になります。今回は定期的に画像を解析するため “インターバルタイマー” を選択しています。解析するタイミングとしては他にも、ゴミ出しの日の 午前8時に「ゴミの状態」を判定したい場合などは “スケジュールタイマー”、在庫の変動があった時に、在庫状況を判定させる場合は “ソラカメモーション検知/サウンド検知” を選択することが可能です。
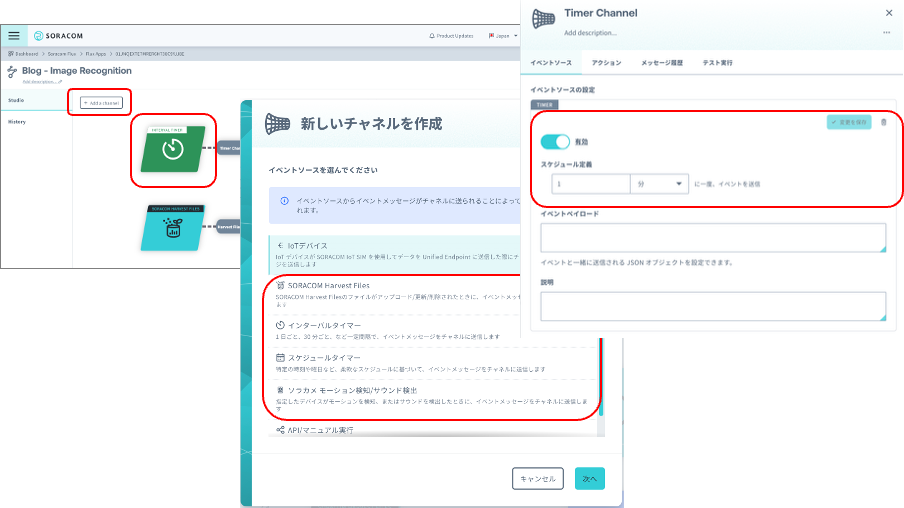
図6:カメラ画像の取得タイミング
取得した画像を処理する際に設定するのがアクションになります。図7 がカメラの画像の出力方法を設定するアクションの画面になります(チャネルのアクションタブから追加できます)。SORACOM API を選択し、”exportSoraCamDeviceRecordedImage” API を検索し、URL の “{device_id}” のところに、“7CDDXXXXXXX” のように、画像認識に利用するソラカメのカメラの ID を指定します。また Body で静止画の設定を行っています。”time“:${now()} は、最新の静止画の出力する設定、”imageFilters“: [“wide_angle_correction“] はソラカメの広角レンズで取得される画像の歪みを補正するオプションになります。そして、”harvestFiles” で、SORACOM Harvest Files の保存先を指定しています({device_id}はシステム内で自動的にカメラの ID に補完されるため、このままで大丈夫です。)。
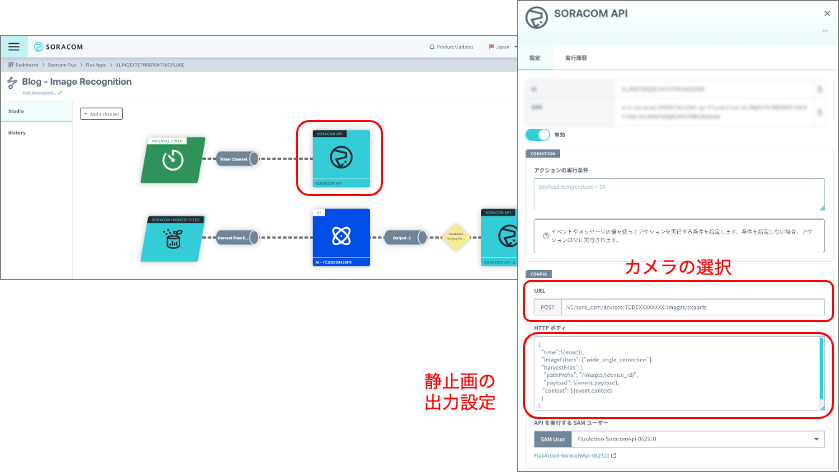
| カメラの選択(XXXXXXXXはカメラの ID) | POST: /v1/sora_cam/devices/7CDDXXXXXXXX/images/exports |
| 静止画の出力設定 | { “time”:${now()}, “imageFilters”:[“wide_angle_correction”], “harvestFiles”: { “pathPrefix”: “/images/{device_id}”, “payload”: ${event.payload}, “context”: ${event.context} } } |
図7:カメラの画像の出力方法の設定
カメラ画像の解析のフロー
SORACOM Harvest Files に画像が保管されたことを契機にして、画像解析を行うフローを作成します。最初にアクション(SORACOM Harvest Files)を作成します。
図8が SORACOM Harvest Files の設定画面になります。ファイルパスでは、静止画の出力設定の際に指定したパス(“/images/7CDDXXXXXXX”)に、ファイルが作成される/更新されると、後段の AI による画像認識が行われます。
この設定をすることによって、SORACOM Harvest Files のメニューから、指定したパスに、直接画像をアップロードすると、画像認識が行われる様になります。今回の画像の一部はスマホで撮影しているため、これらの画像は、SORACOM Harvest Files へ直接アップロードして画像認識を行いました。またプロンプトを何度も修正して結果を確認するために、同じ画像をアップロードした場合にも解析が行われるように、イベントタイプとしてファイル作成だけではなく、ファイル更新も選択しています。
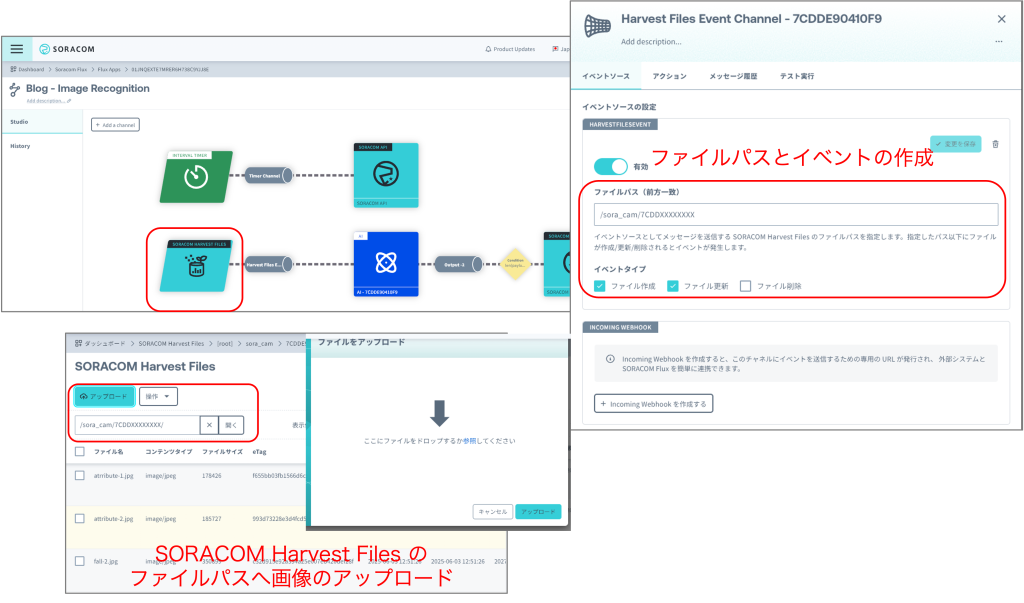
図8:SORACOM Harvest Files の設定
SORACOM Harvest Files Event Channel のアクションとして、AI を追加し、SORACOM Harvest Files にアップロードされた画像を AI で解析します。図9が AI アクションの設定画面になります。この画面から、画像解析に利用する AI のモデルおよびプロンプトを入力することができます。SORACOM Flux では様々な AI のモデルを選択することが可能になっています。今回はコストと画像認識の性能を鑑みて “Google Gemini 2.0 Flush” を選択しています。AI モデルの選択の下にあるのがプロンプトの入力画面になっていて、こちらに認識させる画像に合わせて、プロンプトを入力します。画像認識結果を JSON で取得するため 「AI からの返答を JSON 形式にする」と「AI に画像を読み込ませる」へ両方チェックを入れてください。
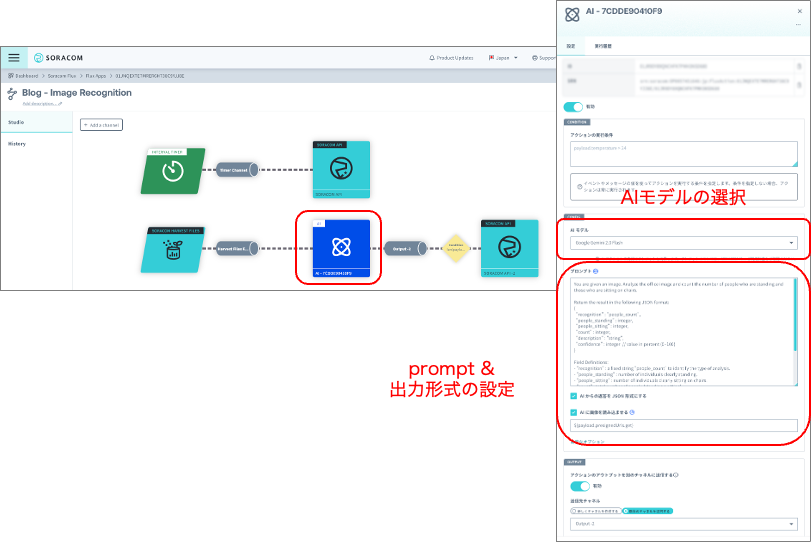
| AI モデルの選択 | Google Gemini 2.0 Flash |
| ☑️ボックス | AI からの返答を JSON 形式にするAI に画像を読み込ませる |
図9:AI モデルおよび、プロンプトの入力
AI の認識結果を保存するため、output に SORACOM API アクションを追加します。SORACOM Harvest Data へ結果を保存するアクションの設定画面が図10になります。SORACOM API を選択し、”createSoraCamDeviceDataEntry” API を検索して、先ほどと同様に URL の “{device_id}” に、契約しているソラカメのカメラの ID を指定してください。アクションの実行条件を設定することによって、AI からエラーが返ってきた場合に、データを廃棄して、認識結果のみを保存する様にしています。HTTP ボディでは、SORACOM Harvest Data に保存される最終的なデータフォーマットを指定しています。ここでは認識結果(result)と認識に利用した静止画(imageUrl)と共に、認識に利用した AI のモデル(payload.usage.model)を含める様にしています。
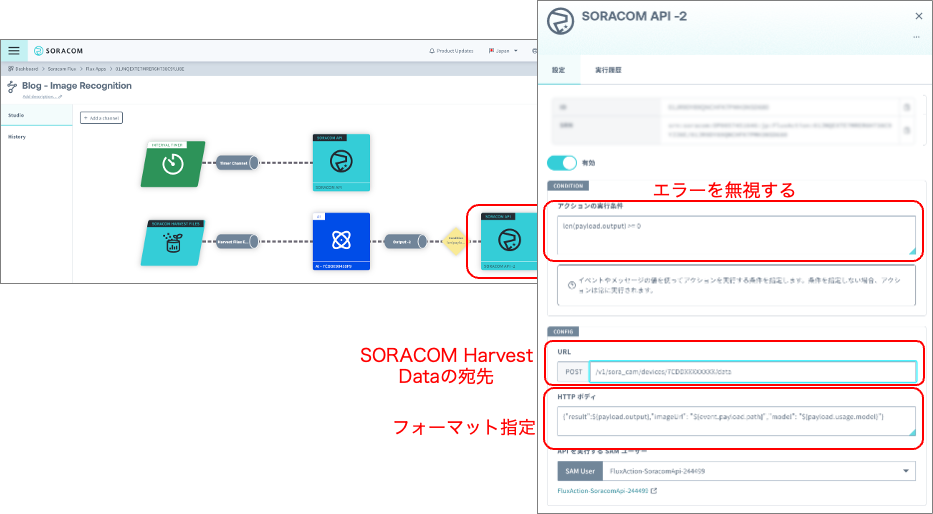
| アクション実行の条件 | len(payload.output) >= 0 |
| URL | /v1/sora_cam/devices/7CDDEXXXXXXXX/data |
| HTTP ボディ | { “result”:${payload.output}, “imageUrl”:”${event.payload.path}”, “model”: “${payload.usage.model}” } |
図10: 認識結果のフォーマット
認識結果の確認
図11は SORACOM Harvest Data を利用して認識結果を確認する画面になります。SORACOM Harvest Data の画面から、リソース→ソラカメ→対象のカメラ(今回の例では 7CDDEXXXXXXXX)を選択すれば、選択した期間のデータが表示されます(この例では直近1時間を指定)。数値データについては、グラフとして表示することが可能です。
レシピではさらに SORACOM Lagoon を利用し、解析に利用した画像とデータを合わせて確認するダッシュボードの作成方法も説明されているので、参考にしてみてください。
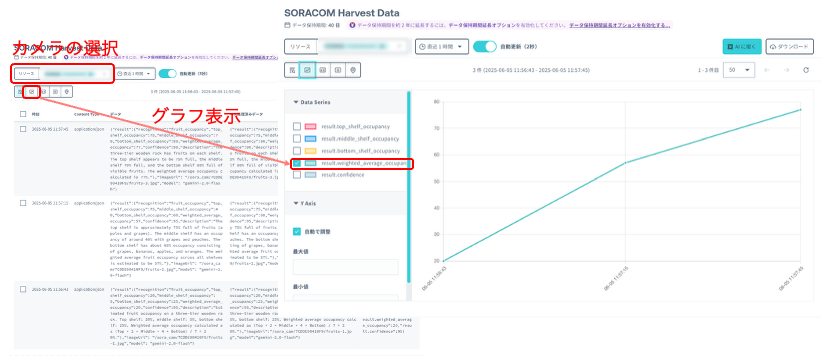
図11:SORACOM Harvest Data
画像認識の停止
検証が終わったら、画像認識を停止させます。図12に表示した、カメラ画像を取得するチャネル(インターバルタイマー)の設定画面を開いて、無効にすることで停止することが可能です。
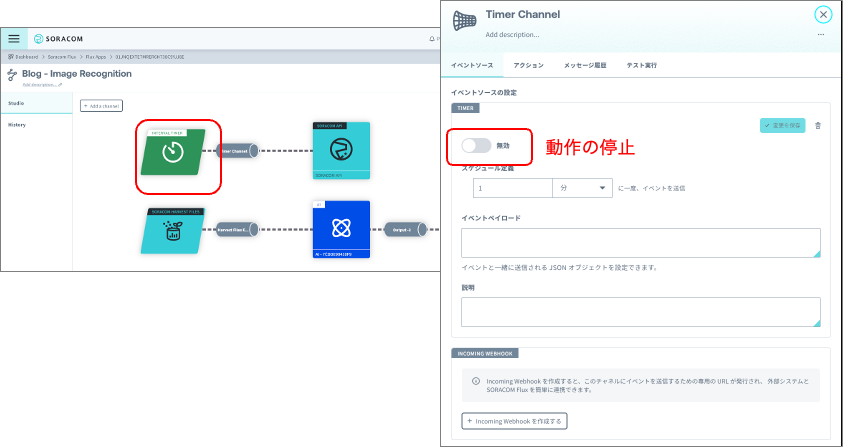
図12:画像認識の停止
トラブルシュート
結果が確認できない場合は、それぞれのステップにおいて実行結果を確認する “メッセージ履歴” タブを確認してください。例えば、図13 SORACOM Harvest Data のアクションの設定画面で、間違った URL を指定した場合、実行履歴を確認すると Error(HTTP 400) とエラー内容を確認することができます。それぞれのステップでエラーが起きていないかをチェックして、これまでの設定が正しく反映されてることをご確認ください。
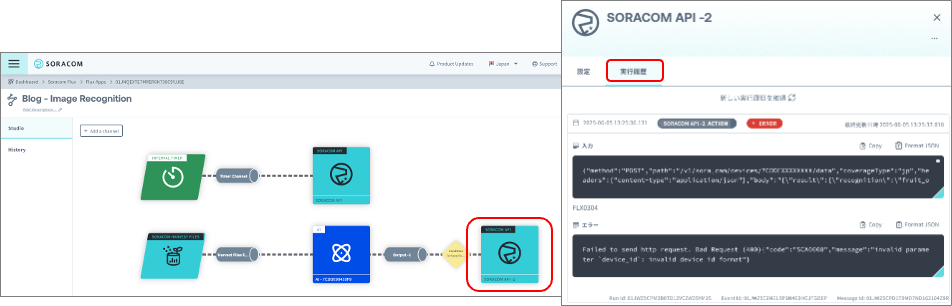
図13:SORACOM Flux のエラーの確認方法
まとめ
Amazon Nova Lite、 Google Gemini 2.0 Flash などの軽量なモデルの登場により、生成 AI を利用した画像認識のコストが大幅に下がってきました。生成 AI を利用した画像認識はプロンプトを変更するだけで、様々な画像認識に対応できるという柔軟性を備えています。このブログでは、身近な課題を解決する画像認識に使えるプロンプトを用意して、Google Gemini 2.0 Flash でどこまで解析できるのかを試しました。全ての画像認識において、十分な精度を得られるという素晴らしい結果になりました。
ソラコムのサービスを組みわせることによって、カメラ⇨生成 AI を利用した認識⇨結果の確認までのシステムを簡単に構築可能です。この構成を一度作れば、プロンプトを変更することで、他の様々な画像認識に対応することができるため、プロンプトの作成に集中することが可能になります。皆様も是非プロンプトを作成して、独自の画像認識を試してみて下さい。
最後に、2025年7月16日にソラコムの年次カンファレンスである SORACOM Discovery 2025 が東京ミッドタウンで開催されます。今年のテーマは「Crossroad~IoT×AIが交差する未来~」ということで、IoTxAI に関する展示も多数ございますので、皆様ぜひご参加ください。
― ソラコム 五十嵐 (Ash)
参考資料
その他のプロンプト一覧
表6にその他の画像認識に利用したプロンプトの一覧を示します。
表6: 利用した prompt 一覧
| プロンプト | プロンプトの日本語訳 | |
オフィスの混雑度 | You are given an image. Analyze the office image and count the number of people who are standing and those who are sitting on chairs. Return the result in the following JSON format: {Field Definitions: - "recognition" : a fixed string "people_count" to identify the type of analysis.Return only the JSON. Do not include any extra commentary or formatting. | 画像が与えられる。オフィスの画像を分析し、立っている人と椅子に座っている人の数を数えてください。 結果を以下の JSON 形式で返してください。 {フィールド定義: - "recognition" : 分析の種類を識別するための固定文字列 "people_count"。JSONのみを返す。追加のコメントやフォーマットは含めないでください。 |
転倒者検知 | You are given an image. Please analyze it and count the number of people who appear to have fallen (i.e., are lying unnaturally on the ground) and the number of people who are not fallen (i.e., sitting, standing, or otherwise in a normal posture). Return the result in the following JSON format: {Field Definitions: - "algorithm" : a fixed string "fall_people count" to identify the task.Return only the JSON. Do not include any extra commentary or formatting. | 画像が与えられる。画像を分析し、転倒しているように見える人(不自然に地面に横たわっている人)の数と、転倒していない人(座っている、立っている、またはその他の通常の姿勢の人)の数を数えてください。結果を以下の JSON 形式で返してください。{フィールド定義: - "algorithm" : タスクを識別するための固定文字列 "fall_people count"。JSON のみを返す。余分なコメントやフォーマットは含めないでください。 |
人物属性 | Please analyze the image and count the number of male and female individuals. Also, estimate how many people fall into each age range group for each gender. Return the result in the following JSON format: {Field Definitions: - "algorithm" : fixed string "person_attribute" to indicate the task performed.Return only the JSON. Do not include any extra commentary or formatting. | 画像を分析し、男性と女性の数を数えてください。また、各性別ごとに各年齢層グループに属する人数を推定してください。 結果を以下の JSON 形式で返してください。 {フィールド定義: - "algorithm" : 実行されたタスクを示す固定文字列 "person_attribute"。JSON のみを返す。余分なコメントやフォーマットは含めないでください。 |
乗り物の判別 | You are analyzing a photo of a parking lot. Based on the image, return the result in the following JSON format:{Field Definitions: - "recognition" : a fixed string "vehicle_count" to label the recognition.Return only the JSON. Do not include any extra commentary or formatting. | あなたは駐車場の写真を分析しています。画像に基づいて、以下の JSON 形式で結果を返してください。{フィールド定義: - "recognition" : 解析結果をラベル付けるための固定文字列 "vehicle_count"。JSONのみを返す。余分なコメントやフォーマットは含めないでください。 |
天気の判別 | You are analyzing a photo of the weather. Based on the image, return the result in the following JSON format:{Field Definitions: - "recognition" : a fixed string "weather" to label the recognition.Return only the JSON. Do not include any extra commentary or formatting. | なたは天気の写真を分析しています。画像に基づいて、以下のJSON形式で結果を返してください:{フィールド定義: - "recognition": 解析を区別するための固定文字列 "weather"。JSONのみを返す。追加のコメントやフォーマットは含めない。 |
オフィスの混雑度
折角、オフィスに出社したのに、オフィスが混んでいて席がないという経験から、オフィスの混雑度判定を行いました。単純に人数だけではなく、立っている人と座っている人を区別して出力するプロンプトを作成し、より正確にオフィスにオフィスの状況を把握することを試みました。
図14が認識結果になります。図中の円で囲んだところには座っている人、長方形で囲んだところには立っている人がいる場所を私が手動でマーキングしています。マーキング前の写真を認識させた結果、左の図は立っている人1名、座っている人6名、右の図は、立っている人2名、座っている人3名と両方共に座っている人と、立っている人の数が正しく認識されました。confidence を 95% で返していることからも、人間について、かなりの精度で判定できることが分かりました。

図14:オフィスの混雑度の認識結果
転倒者検知
転倒者検知は、今回利用したSORACOM Flux のデモ動画でも利用されたので、私も試してみました。図15の左の図では、一人が転倒判定、もう一人は肘と膝をついているので転倒ではないと判定されています。一方で右の図では二人ともが完全に転倒しているという判定となりました。転倒検知では、膝や肘をついておらずに、完全に転倒したというレベルでしっかりと判定ができていることが分かりました。

図15:転倒者検知の認識結果
人物属性
画像認識の例でよく見るのが、人物属性の判定です。プロンプトでは、それぞれの年齢や性別だけではなく、統計情報を出力するために、“male_age_0_10”: xx、“female_age_0_10”: yy の様に、女性と男性の年代ごとの数も結果として返すようにしました。 図16 が認識結果になります。左側の認識結果を見ると男性が5人、女性が1人と正確に認識されていることが分かります。右の図では、画面に映っているリモート参加の男性を含めて、男性が6名、女性が1名と正確に認識されました。

図16:人物属性の認識結果
乗り物の判別
我が家の周りは道が狭いので、度々違法駐車などで、車が滞留することがありました。そこで、定番ではありますが、乗り物の認識を行いました。図17が認識結果になります。“car_count”:4 となり、写真に写っている4台の車がしっかりと認識されています。左の図は正面から駐車している車を写した写真になっており、しっかりと4台の車が解析されました。右の図は引いた画角で公道を撮影したものになります。3台の車とともに、バイク、そして左の奥のビルの前に停められている自転車もしっかりと、しっかりと解析されました。物体解析でよく利用される coco dataset では、他にも自転車、トラック、バスなどが含まれているので、これらの乗り物も区別して解析されるかもしれません。

図17:乗り物の認識結果
天気の判別
ソラカメのユーザ様の事例として、全国各地の空の模様を24時間共有する、株式会社ウェザーニューズ社の「Myライブカメラ」があることもあり、空の様子から天気の判別を試しました。プロンプトでは、天気が雪、雨、曇り、晴天のどれなのかを判別できる様にしました。図18が雪、雨、一部青空が見えている場合の認識結果になります。左の図では “snow: 1, “cloudy”: 1 というように、曇りかつ雪であることを正しく認識しています。真ん中の図でも同様に曇りかつ雨 (“rain”: 1、”cloudy”: 1)であることを正しく認識しています。そして右の図では少し雲があるが晴天になっている(”cloudy”:1、”clear”: 1)ことを正しく認識しました。今回は空だけではなくて、地面を写したこともあり、天気についても正しく認識されることがわかりました。
