皆様、こんにちは。ソリューションアーキテクトの松永(ニックネーム:taketo)です。
IoTプロジェクトのクラウドへの連携が加速している一方で、最近ではChatGPTをはじめとしてAI・機械学習やデータ分析の社会実装も普通になってきましたね。今回は、Amazon KinesisとSORACOMを使ったリアルタイム分析をご紹介致します。
先日、ブログ「Google CloudとSORACOMでリアルタイム分析とAI・機械学習」にてGoogle Cloudを使った例も掲載しておりますので、良ければご覧ください。
少し長いのでハンズオンで検証しなくとも全体のコードの流れを追って頂くのも良いと思います。是非ご一読ください!それでは早速行ってみましょう!
アーキテクチャ
はじめに、今回の検証で構築するアーキテクチャをご説明します。
今回例として 気象データを扱うIoTプロジェクトを想定し、東京や大阪といった地域ごとにデバイスが1つずつ配置されていることを前提としています。デバイスでは、定期的に温度を計測し位置情報を送信、また同時に未来の気温を予測する仕組みを想定します。
アーキテクチャでは大きく「データアップロード」「モデル構築」「デバイス制御」する流れがあります。「データアップロード」では、デバイスから「simId」「時刻」「温度」が定期的に送信され、各地域で3時間ごとの平均気温をAmazon Kinesis Data Analyticsを使ってリアルタイムに計算する仕組みを構築します。各地域ごとに集約する部分では、地域ごとに1つのデバイスを配置しているという前提に基づき、「simId」でグループ処理をすることとしています。また今回は検証目的として計算結果を単純にログ出力するAWS Lambdaに連携するアーキテクチャとしておりますが、AI・機械学習を検討の方は、Amazon DynamoDBやAmazon S3へ集約するのが良いでしょう。
本ブログでは、デバイスはPCにSORACOM Arcを稼働させて動作を模擬しております。お客様の環境では SORACOM Arc、または SORACOM IoT Simを利用することでデバイスの動作を実装してください。
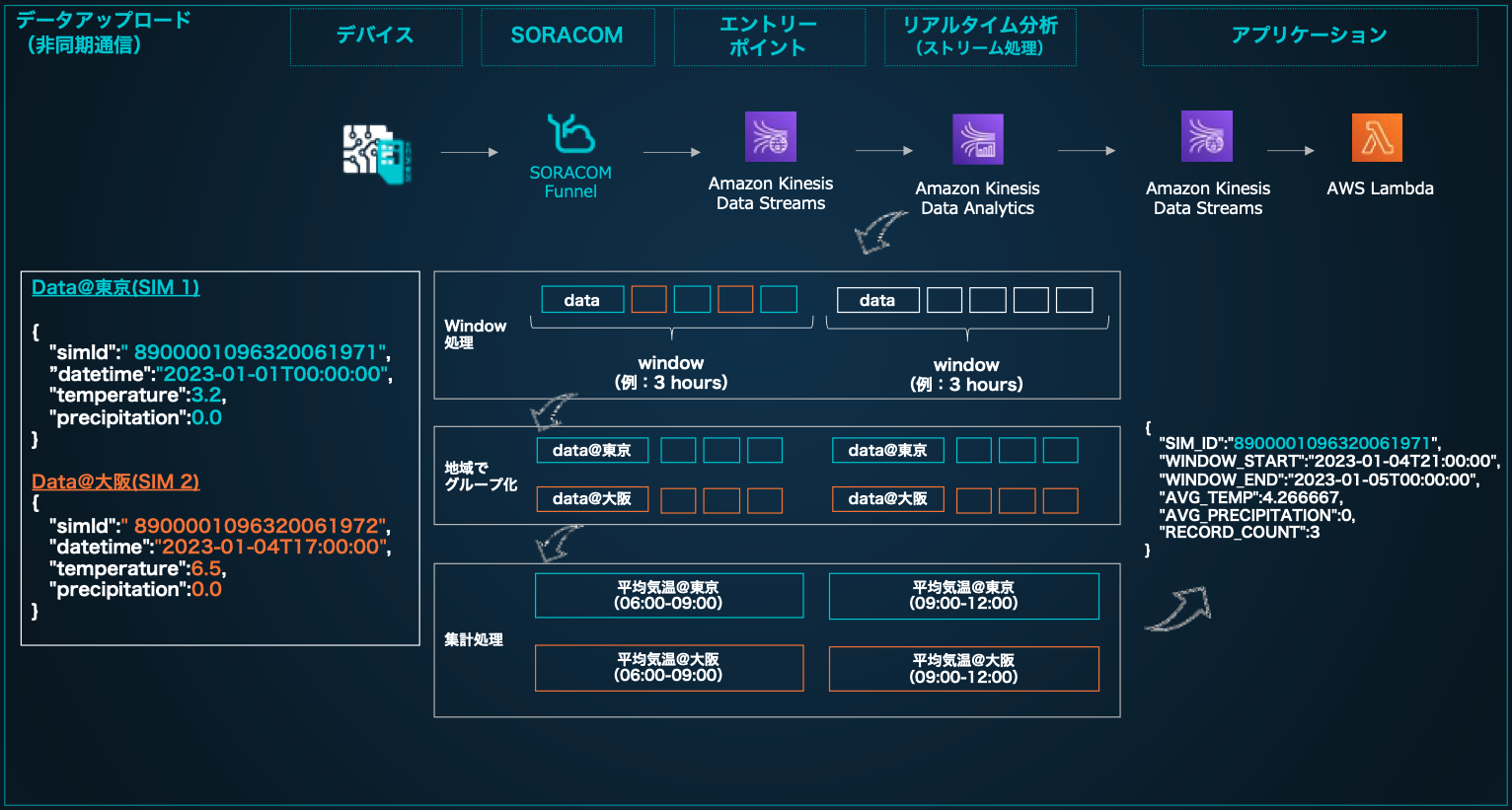
リアルタイム分析システムを構築
それでは早速リアルタイム分析システムを構築していきましょう。
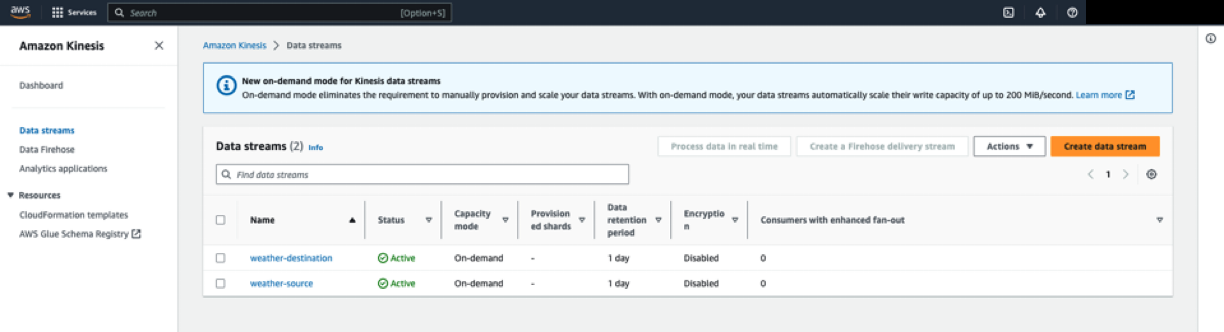
Kinesis Data Streamの作成
今回は2つのKinesis Data Streamを作成してください。
weather-destination:SORACOM Funnelから連携するためのStreamweather-source:解析結果を出力するStream
IAMロールの作成
SORACOM FunnelがKinesis Data Streamへデータを送信するためのIAMロールを作成します。
IAM Policyには、作成した weather-source へ kinesis:PutRecord kinesis:PutRecords する権限を設定してください。
| { “Version”: “2012-10-17”, “Statement”: [ { “Sid”: “VisualEditor0”, “Effect”: “Allow”, “Action”: [ “kinesis:PutRecord”, “kinesis:PutRecords” ], “Resource”: “arn:aws:kinesis:us-west-2:9039********:stream/weather-source” } ] } |
SORACOMのAWSアカウントへ権限の利用を許可するために、IAMロール作成画面で利用を許可してください。
- 日本カバレッジ:
762707677580 - グローバルカバレッジ:
950858143650

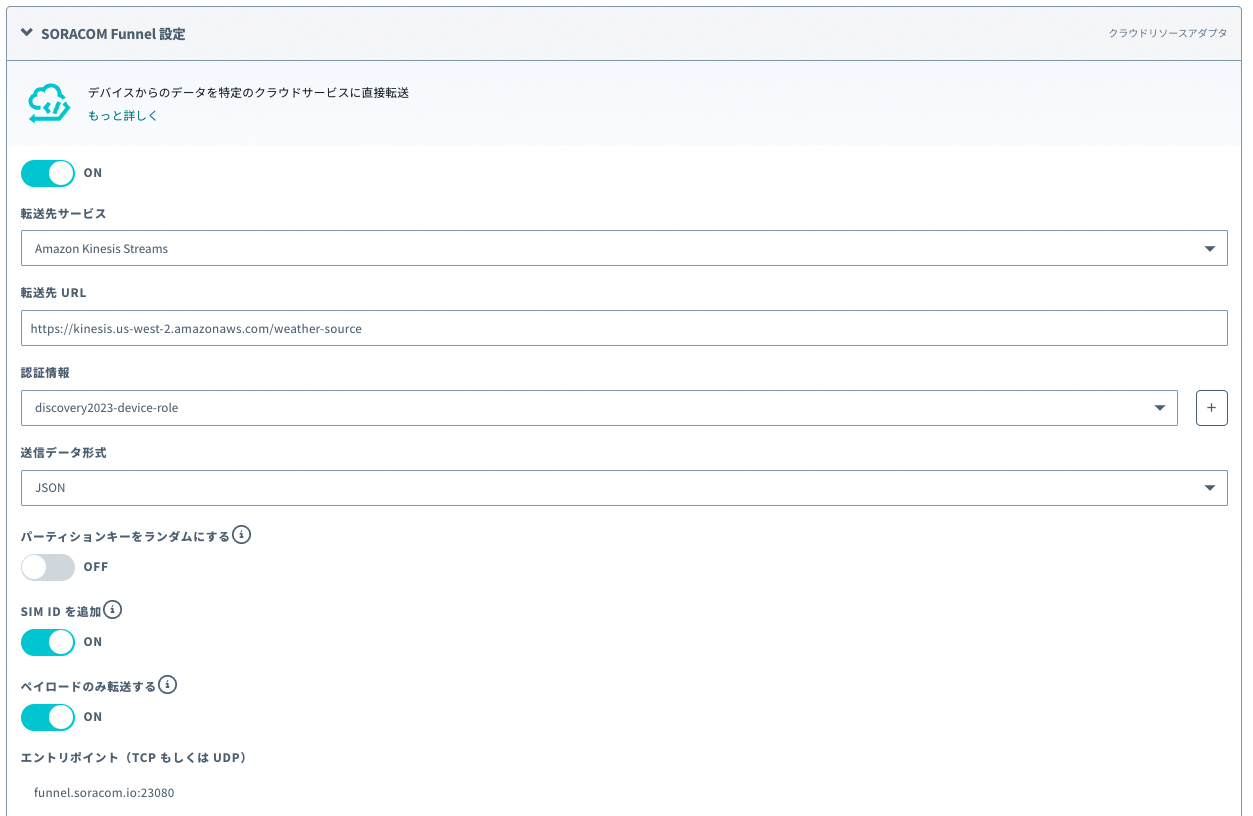
SORACOM Funnelの設定
デバイスからFunnelのエンドポイントへ送信されるデータを先ほど作成してKinesis Data Streamへ連携する設定をしていきます。
IAM Roleの登録
SORACOM FunnelがデータをKinesis Data Streamを利用する際に必要な権限情報をSORACOMの認証ストアに登録します。
ユーザードキュメント「認証情報を登録する」を参考に、先ほど作成した「AWS IAM ロール認証情報」を登録してください。
SORACOM Funnel設定
Kinesis Data Analyticsの設定
それでは、Kinesys Data Analyticsを作成し、リアルタイム分析する設定をしていきましょう。
Kinesys Data AnalyticsはApache FlinkというOSSがベースとなっており、大規模データの分散処理が可能となっています。
分散処理のジョブを作成し、常駐アプリケーションとして常に分析を実行する分析基盤としても構築可能ですが、今回はインタラクティブにジョブの操作が可能なNotebookインスタンスを立ち上げて設定をしていきます。
Kinesis Data Analytics作成
まずは、NotebookをKinesis Data Analytics画面から作成してください。
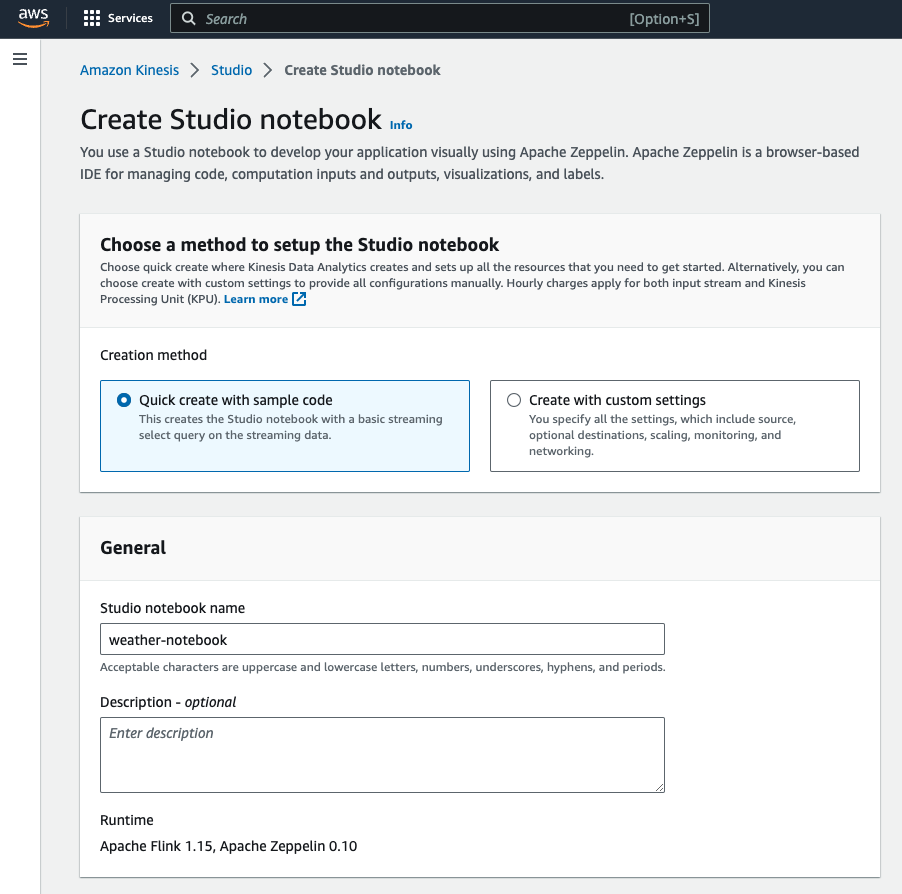
Notebook開発
作成したNotebookインスタンスにログインし、セルに以下のコードをコピー&ペーストして「Ctrl + Enter」を押して実行してください。
1つ目のセルでは、`weather-source`というKinesys Data Streamからデータを読み取る処理を書いています。
Tableを作成しておりますが、このSQLを実行するとAWS Glueのデータベースにテーブルが作成されます。
%flink.ssql(type=update)
DROP TABLE IF EXISTS weather_data;
CREATE TABLE weather_data (
simId VARCHAR,
datetime TIMESTAMP(3),
temp FLOAT,
precipitation INTEGER,
WATERMARK FOR datetime AS datetime - INTERVAL '5' SECOND
)
PARTITIONED BY (simId)
WITH (
'connector' = 'kinesis',
'stream' = 'weather-source',
'aws.region' = 'us-west-2',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);次に、新しいセルに以下のコードをコピー&ペーストし同じく実行してください。
ここではこの後でWindow処理による統計処理を施した結果を格納するテーブルを作成しています。
ここで、’connector’ = ‘kinesis’, `’stream’ = ‘weather-destination’`を指定することで先ほど作成したKinesis Data Steamの`weather-destination`へ処理結果が連携されます。AWS LambdaはこれをSubscribeすれば良いということですね!
%flink.ssql(type=update)
DROP TABLE IF EXISTS weather_data_output;
CREATE TABLE weather_data_output (
SIM_ID VARCHAR,
WINDOW_START TIMESTAMP(3),
WINDOW_END TIMESTAMP(3),
AVG_TEMP FLOAT,
AVG_PRECIPITATION FLOAT,
RECORD_COUNT BIGINT
)
WITH (
'connector' = 'kinesis',
'stream' = 'weather-destination',
'aws.region' = 'us-west-2',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
);次に、新しいセルに以下のコードをコピー&ペーストし同じく実行してください。
ここでは、タイムスタンプを元に3時間ごとにWindow処理を施しています。Window処理とは、纏まった期間で処理することですが、ここでは3時間ごとに平均気温や平均降水量を計算しています。
%flink.ssql(type=update)
INSERT INTO weather_data_output
SELECT
simId as SIM_ID,
TUMBLE_START(datetime, INTERVAL '3' HOUR) as WINDOW_START,
TUMBLE_END(datetime, INTERVAL '3' HOUR) as WINDOW_END,
AVG(temp) as AVG_TEMP,
AVG(precipitation) as AVG_PRECIPITATION,
COUNT(*) as RECORD_COUNT
FROM
weather_data
GROUP BY
simId,
TUMBLE(datetime, INTERVAL '3' HOUR);AWS Lambdaの作成
最後に、リアルタイム分析した結果を出力するAWS Lambdaを作成してください。
このAWS LambdaのTriggerに作成した、Kinesis Data Steamの`weather-destination`を指定してください。
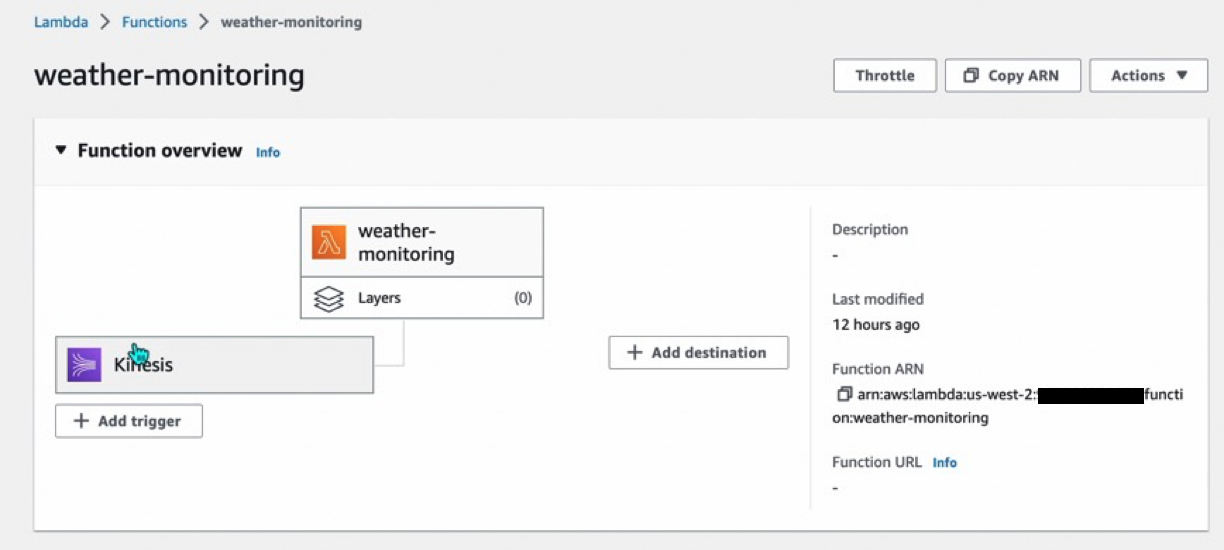
今回は、検証用途として分析結果をログ出力する設定をしています。
稼働確認
それでは、早速デバイスからデータを送信してみましょう。
テストデータについては、1時間ごとの気象庁のホームページから過去のデータをダウンロードできます。
本ブログでは、デバイスはPCにSORACOM Arcを稼働させて動作を模擬しております。お客様の環境では SORACOM Arc、または SORACOM IoT Simを利用することでデバイスの動作を実装してください。
デバイス(PC)からは、Jupyternotebookを立ち上げ、SORACOM Funnelへデータを送信しています。

すると、AWS LambdaのCloud Watchログに3時間ごとの平均気温など統計情報が出力されていることが確認できました。
リアルタイム処理ができていますね!

アーキテクチャ例:AI・機械学習やアプリケーションからのデバイス制御
これまでは、検証のアーキテクチャでAmazon Kinesis Data Analyticsを重点的にご説明いたしました。
本番のシステムでは、平「データアップロード」「機械学習」「デバイス制御」といった処理がIoTプロジェクト全体で必要になるでしょう。
そのアーキテクチャの一例を下に記載していますが、少し説明させて頂きます。
1. データアップロード:ストリーム処理によるリアルタイム分析とデータ集約 を行います。本ブログでご紹介したAmazon Kinesis Data Analyticsを利用して、効率的に統計処理した情報をデータレイクに蓄積していきます。
2. 機械学習: 機械学習のモデル構築。Amazon S3に格納されたデータを元に、Amazon SageMakerを使ってAI・機械学習モデルを構築していきます。Amazon SageMakerで作成したモデルを推論するためのエンドポイントを作成することも可能です。(参考:「Amazon Web Servicesブログ:Amazon SageMaker エンドポイントとAWS Lambdaを使って、YOLOv5の推論をスケールさせる」)
3. デバイス制御:
デバイスとクラウドを繋げデバイスを制御する仕組みです。下のアーキテクチャ例では、SORACOM Beam経由でIoT CoreにMQTT通信で接続しクラウドとデバイス双方から通信が可能な仕組みを構築しています。接続方法は、「ユーザードキュメント:IoT Coreと接続する」をご覧ください。
また、SORACOM FunkからAWS Lambda経由でAmazon SageMakerを呼び出しているフローは、Amazon SageMakerの推論エンドポイントをデバイスから呼ぶ処理を想定しています。今回の例ですと、特定の時間の平均気温をデバイスから予測するといったことも可能ですね。SORACOM FunkでAWS Lambdaを呼び出す方法は「ユーザードキュメント:AWS Lambda を実行し Slack へ通知する」を参考にしてみてください。2023年にリリースした機能で、SORACOM Beam経由でAmazon SageMakerを呼び出す方法もありますので、「ユーザードキュメント:IAM 認証を利用して Amazon SageMaker にデータを送信して推論する」もご覧ください。

おわりに
いかがでしたでしょうか?
今回は、リアルタイムに特定の時間で分析を纏めて処理するWindow処理と統計処理を行う高度な処理ができました。リアルタイム分析をせずに、一度データベースに格納し分析する手法も多く採用されることもありますが、より効率的に大規模なデータを扱う場合に今回ご紹介したアプローチが良いでしょう。
是非参考にして頂き、分析やAI・機械学習にも取り組んでみてくださいね!
― ソラコム松永 (taketo)