こんにちは、ソラコムの松下(Max)です。
ChatGPTをはじめとして、今話題の「生成 AI」について、現状の振り返りとこれからの付き合い方について、11/11に開催された「オープンセミナー@広島 2023」でお話する機会がありました。
このブログでは、資料の紹介とともに登壇内容の解説をしていきます。生成AIは今後も発展が予想されます。その中で、新機能や情報をうまく掴んでいただくための基礎力やポイントを紹介しています。
資料は本ブログの最後に掲載しています。最後までぜひお読みください。
IoTと生成AIの関係、ソラコムの生成AIへの取り組み
IoTはセンサーやカメラ等を用いて現場をデジタル化し、ネットワークを通じてクラウドでデジタルデータを活かす技術です。ソラコムは IoT プラットフォーム「SORACOM」を通じて、IoTにおける「つなぐ」を簡単にするサービスを提供しています。
ソラコムでは現在、生成AIに対して3つの取り組みを行っています。
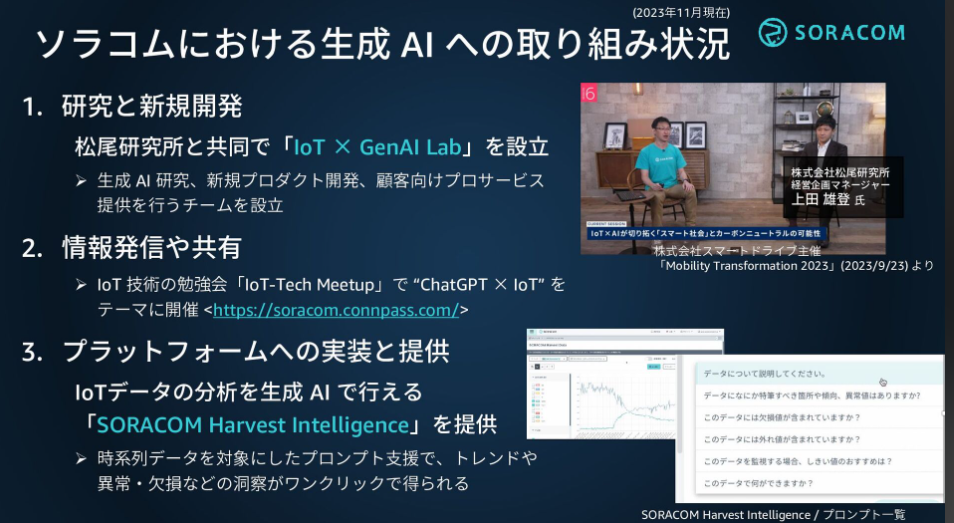
1つ目が、研究と新規開発です。AI技術の社会実装に強みを持つ「株式会社松尾研究所」と共に「IoT × GenAI Lab」を設立しました(参考: プレスリリース)。研究だけでなく新規プロダクト開発や、お客様とともに生成AIの社会実装を行うチームです。
2つ目が、情報発信や共有です。ソラコムでは、IoTを中心に “専門知識が無くとも簡単に使える = 民主化” を推し進めており、生成AIやLLMも同様です。情報共有は民主化の1つとして、IoT技術の勉強会「IoT-Tech Meetup」にて、ChatGPTをテーマにした回を2023年5月に行いました。
3つ目が、SORACOM プラットフォームへの実装です。IoTでは、時間の経過に従って測定されたデータ「時系列データ」を分析・活用することが非常に多いです。この分析作業を生成AIで簡単に行える機能を2023年7月に「SORACOM Harvest Intelligence」を提供開始しています(参考: プレスリリース)
このように、IoTデータ分野を軸に生成AIの活用について取り組みを進めています。
生成AI や LLM、基盤モデル(Foundation Model)の振り返り
生成AI には様々な単語が出てきます。これらの単語を知ることが、理解を深める第一歩となるため、知っておきたい単語を解説しました。

“AI カテゴリー” における、生成AIの位置づけ
機械学習(ML)やディープラーニング(DL)には、データを条件に沿って分類をする「識別モデル」と、指定領域のデータを生成する「生成モデル」がありますが、このうち後者の生成モデルを特に注目した呼び名が生成AIです。
これまでの ML や DL と生成AIが異なる点
これまでの ML/DL は、ML/DL に仕事をさせる前には「学習」を行い “モデル” を作る作業がありました。生成AIでは「基盤モデル (Foundation Model)」という、いわば学習済みモデルがあり、それを利用します。学習作業が不要で始められる事が、これまでの ML/DL と異なる点です。
基盤モデル (Foundation Model) とは
基盤モデルは、以下のように解説されています。
大量かつ多様なデータで訓練され、多様な用途におけるタスクに適応できるモデル
Stanford University Human-Centered Artificial Intelligence, Machine Learning Reflections on Foundation Models
“大量かつ多様” と表現がされていますが、たとえば ChatGPT の基盤モデルの1つ「GPT-3」では、4兆を超える単語を基に学習しています(*1)。このくらい膨大な情報を抱えた基盤モデルは “常識” に近い知識の集合体とも言えます。
この基盤モデルの中でも、自然言語を扱う大規模言語モデルが「LLM (Large Language Model)」です。
*1 出所: 松尾豊. “AIの進化と日本の戦略”. 自民党AIの進化と実装に関するプロジェクトチーム(第2回).2020-02-17. https://note.com/akihisa_shiozaki/n/n4c126c27fd3d, (参照 2023-08-10).
LLM が知っている情報を引き出す手法「プロンプトエンジニアリング」
LLM は膨大な情報を持っています。その情報を期待通りに引き出すことで、LLM はより役立ちます。この「情報を引き出すための問い合わせ手法」がプロンプトエンジニアリングです。
例えば下図の左における一般的な問いには、一般論が返ってきています。右ではより詳しいシチュエーションを与えたことで、具体的な回答が得られています。
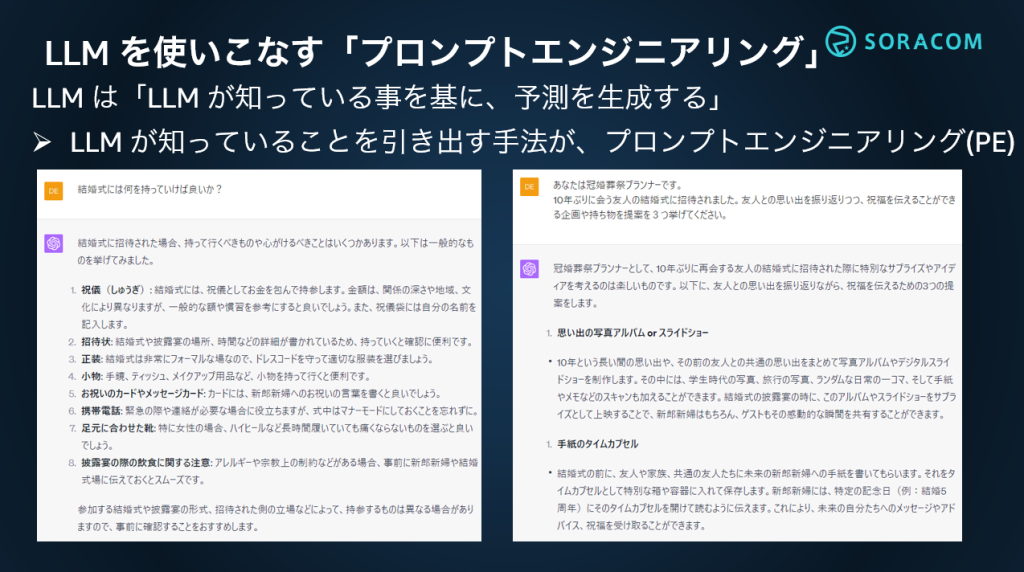
このように問いの具体性や LLM に与える情報によって、期待に沿った回答が得られる可能性が高まるわけです。
プロンプトエンジニアリングで、まず知っておきたい書き方は ChatGPTを提供しているOpenAIのドキュメント「Best practices for prompt engineering with OpenAI API」がおすすめです。量も少なく、即戦力になる書き方が例示されています。より学ぶならば「Prompt Engineering Guide」(日本語版、英語版)があります。
生成AIとの付き合い方は2通り
セッションの後半では、生成AIとの付き合い方の方向性をご紹介しました。大きく2つ考えられます。
1つ目は「Copilot」です。直訳では副操縦士となりますが、私は「よき友」と紹介しました。私たちの生産性を上げるためのお手伝いをしてもらう使い方です。2つ目は「Embed」です。製品に生成AIの力を組み込み、新たな価値や革新を生み出す “部品” としての付き合い方です。
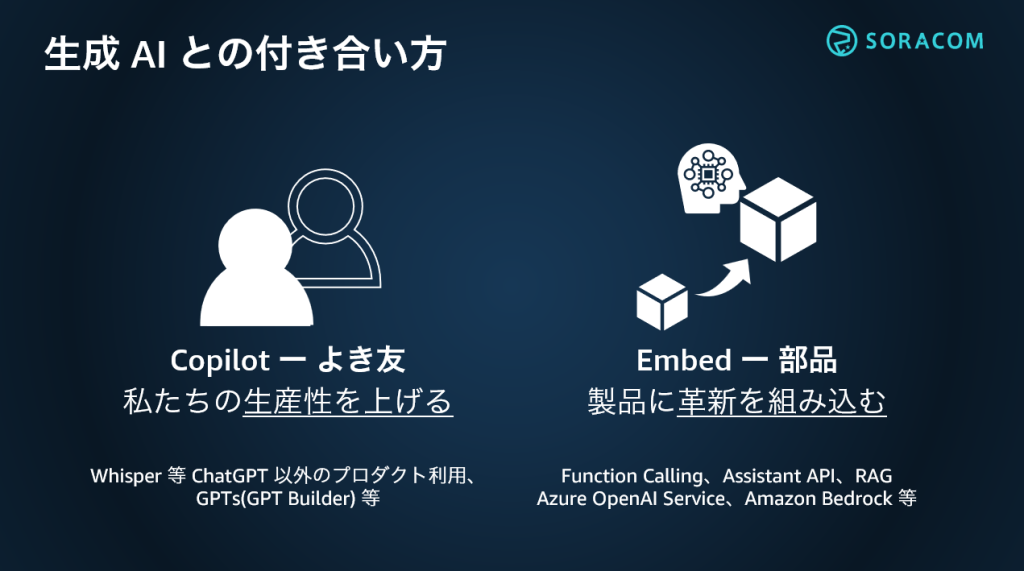
ソラコムでは、ChatGPT の有料プラン(Plus)の利用料金を全額補助してメンバーの利用環境を整えつつ、ガイドラインも策定してブログ記事のレビューや企画作りの壁打ち相手という「よき友」として利用しています。
また 「Embed」 では Azure OpenAI Service を利用して、IoTデータ蓄積サービス「SORACOM Harvest」に生成AIを部品として組み込むことで、先ほどご紹介した SORACOM Harvest Intelligence の提供に至っています。
今後も様々な機能や情報が出てくる事が予想される生成AIですが、付き合い方のスタンスを決めておけば、何に使えそうか?といった分類がしやすいでしょう。
今回の情報が、これから生成AI に取り組む皆さんの道しるべになれば幸いです。
登壇資料
― ソラコム松下 (Max)